2020-07-09: we can fix time-travel in hp_read_swf without changing the fast path. See the addendum.
Back in February 2020, Blelloch and Wei submitted this cool preprint: Concurrent Reference Counting and Resource Management in Wait-free Constant Time. Their work mostly caught my attention because they propose a wait-free implementation of hazard pointers for safe memory reclamation.1 Safe memory reclamation (PDF) is a key component in lock-free algorithms when garbage collection isn’t an option,2 and hazard pointers (PDF) let us bound the amount of resources stranded by delayed cleanups much more tightly than, e.g., epoch reclamation (PDF). However the usual implementation has a loop in its read barriers (in the garbage collection sense), which can be annoying for code generation and bad for worst-case time bounds.
Blelloch and Wei’s wait-free algorithm eliminates that loop… with a construction that stacks two emulated primitives—strong LL/SC, and atomic copy, implemented with the former—on top of what real hardware offers. I see the real value of the construction in proving that wait-freedom is achievable,3 and that the key is atomic memory-memory copies.
In this post, I’ll show how to flatten down that abstraction tower into something practical with a bit of engineering elbow grease, and come up with wait-free alternatives to the usual lock-free hazard pointers that are competitive in the best case. Blelloch and Wei’s insight that hazard pointers can use any wait-free atomic memory-memory copy lets us improve the worst case without impacting the common case!
But first, what are hazard pointers?
Hazard pointers and the safe memory reclamation problem
Hazard pointers were introduced by Maged Michael in Hazard Pointers: Safe Memory Reclamation for Lock-Free Objects (2005, PDF), as the first solution to reclamation races in lock-free code. The introduction includes a concise explanation of the safe memory reclamation (SMR) problem.
When a thread removes a node, it is possible that some other contending thread—in the course of its lock-free operation—has earlier read a reference to that node, and is about to access its contents. If the removing thread were to reclaim the removed node for arbitrary reuse, the contending thread might corrupt the object or some other object that happens to occupy the space of the freed node, return the wrong result, or suffer an access error by dereferencing an invalid pointer value. […] Simply put, the memory reclamation problem is how to allow the memory of removed nodes to be freed (i.e., reused arbitrarily or returned to the OS), while guaranteeing that no thread accesses free memory, and how to do so in a lock-free manner.
In other words, a solution to the SMR problem lets us know when it’s safe to physically release resources that used to be owned by a linked data structure, once all links to these resources have been removed from that data structure (after “logical deletion”). The problem makes intuitive sense for dynamically managed memory, but it applies equally well to any resource (e.g., file descriptors), and its solutions can even be seen as extremely read-optimised reader/writer locks.4
The basic idea behind Hazard Pointers is to have each thread publish to permanently allocated5 hazard pointer records (HP records) the set of resources (pointers) it’s temporarily borrowing from a lock-free data structure. That’s enough information for a background thread to snapshot the current list of resources that have been logically deleted but not yet physically released (the limbo list), scan all records for all threads, and physically release all resources in the snapshot that aren’t in any HP record.
With just enough batching of the limbo list, this scheme can be practical: in practice, lock-free algorithms only need to pin a few (usually one or two) nodes at a time to ensure memory safety. As long as we avoid running arbitrary code while holding hazardous references, we can bound the number of records each thread may need at any one time. Scanning the records thus takes time roughly linear in the number of active threads, and we can amortise that to constant time per deleted item by waiting until the size of the limbo list is greater than a multiple of the number of active threads.6
The tricky bit is figuring out how to reliably publish to a HP record without locking. Hazard pointers simplify that challenge with three observations:
- It’s OK to have arbitrary garbage in a record (let’s disregard language-level7 undefined behaviour), since protected values are only ever subtracted from the limbo list: a garbage record simply doesn’t protect anything.
- It’s also OK to leave a false positive in a record: correctness arguments for hazard pointers already assume each record keeps a different node (resource) alive, and that’s the worst case.
- 1 and 2 mean it doesn’t matter what pinned value we read in a record whose last update was started after we snapshotted the limbo list: resources in the limbo list are unreachable, so freshly pinned resources can’t refer to anything in the snapshot.
This is where the clever bit of hazard pointers comes in: we must make sure that any resource (pointer to a node, etc.) we borrow from a lock-free data structure is immediately protected by a HP record. We can’t make two things happen atomically without locking. Instead, we’ll guess8 what resource we will borrow, publish that guess, and then actually borrow the resource. If we guessed correctly, we can immediately use the borrowed resource; if we were wrong, we must try again.
On an ideal sequentially consistent machine,
the pseudocode looks like the following. The cell argument points to the resource we wish to acquire
(e.g., it’s a reference to the next field in a linked list node), and record is the hazard pointer
record that will protect the value borrowed from cell.
1 2 3 4 5 6 7 | |
In practice, we must make sure that our write to record.pin is visible before re-reading the cell’s value, and we should also make sure the pointer read is ordered with respect to the rest of the calling read-side code.9
1 2 3 4 5 6 7 | |
We need a store/load fence in R1 to make sure the store to the record (just above R1) is visible by the time the second read (R2) executes. Under the TSO memory model implemented by x86 chips (PDF),
this fence is the only one that isn’t implicitly satisfied by the hardware.
It also happens that fences are best implemented with atomic operations
on x86oids,
so we can eliminate the fence in R1
by replacing the store just before R1 with an atomic exchange (fetch-and-set).
The slow cleanup path has its own fence that matches R1 (the one in R2
matches the mutators’ writes to cell).
1 2 3 4 5 6 7 8 9 10 | |
We must make sure all the values in the limbo list we grab in C1
were added to the list (and thus logically deleted) before we read any
of the records in C2, with the acquire read in C1
matching the store-load fence in R1.
It’s important to note that the cleanup loop does not implement
anything like an atomic snapshot of all the records. The reclamation
logic is correct as long as we scan the correct value for records that
have had the same pinned value since before C1: we assume that a
resource only enters the limbo list once all its persistent
references have been cleared (in particular, this means circular
backreferences must be broken before scheduling a node for
destruction), so any newly pinned value cannot refer to any resource
awaiting destruction in the limbo list.10
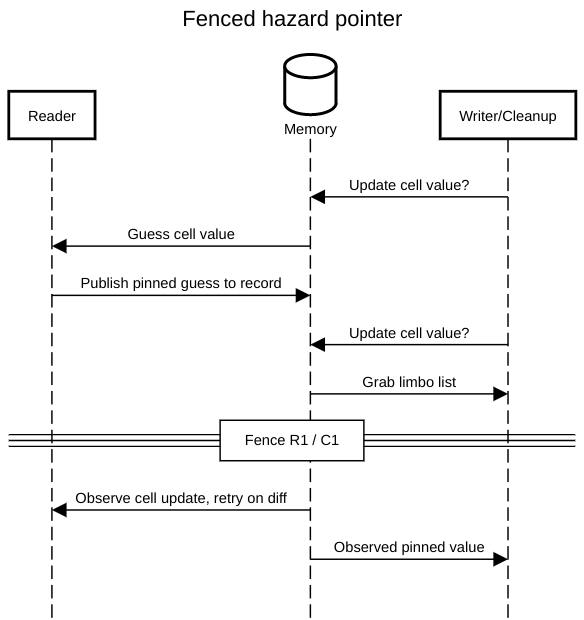
The following sequence diagrams shows how the fencing guarantees that any
iteration of hp_read_explicit will fail if it starts before C1
and observes a stale value.
If the read succeeds, the ordering between R1 and C1 instead
guarantees that the cleanup loop will observed the pinned value
when it reads the record in C2.
This all works, but it’s slow:11 we added an atomic write instruction (or worse, a fence) to a read-only operation. We can do better with a little help from our operating system.
Injecting fences with OS support
When we use fences or memory ordering correctly, there should be
an implicit pairing between fences or ordered operations: we use fencing to
enforce an ordering (one must fully execute before or after another,
overlap is forbidden) between pairs of instructions in different
threads. For example, the pseudocode for hazard pointers with
explicit fencing and memory ordering paired the store-load fence in
R1 with the acquisition of the limbo list in C1.
We only need that pairing very rarely, when a thread actually executes the cleanup function. The amortisation strategy guarantees we don’t scan records all the time, and we can always increase the amortisation factor if we’re generating tiny amounts of garbage very quickly.
It kind of sucks that we have to incur a full fence on the fast read path, when it only matches reads in the cleanup loop maybe as rarely as, e.g., once a second. If we waited long enough on the slow path, we could rely on events like preemption or other interrupts to insert a barrier in all threads that are executing the read-side.
How long is “enough?”
Linux has the membarrier syscall
to block the calling thread until (more than) long enough has elapsed,
Windows has the similar FlushProcessWriteBuffers, and
on other operating systems, we can probably do something useful with scheduler statistics or ask for a new syscall.
Armed with these new blocking system calls, we can replace the store-load fence in R1 with a compiler barrier, and execute a slow membarrier/FlushProcessWriteBuffers after C1.
The cleanup function will then wait long enough12 to ensure that any
read-side operation that had executed before R1 at the time we read the limbo list in C1 will be visible (e.g., because the operating system knows a preemption interrupt executed at least once on each core).
The pseudocode for this asymmetric strategy follows.
1 2 3 4 5 6 7 | |
1 2 3 4 5 6 7 8 9 10 11 | |
We’ve replaced a fence on the fast read path with a compiler barrier, at the expense of executing a heavy syscall on the slow path. That’s usually an advantageous trade-off, and is the preferred implementation strategy for Folly’s hazard pointers.
The ability to pair mere compiler barriers with membarrier
syscalls opens the door for many more “atomic enough” operations, not
just the fenced stores and loads we used until now:
similarly to the key idea in Concurrency Kit’s atomic-free SPMC event count,
we can use non-interlocked read-modify-write instructions,
since any interrupt (please don’t mention imprecise interrupts) will happen before or after any such instruction,
and never in the middle of an instruction.
Let’s use that to simplify wait-free hazard pointers.
Wait-free hazard pointers with interrupt-atomic instructions
The key insight that lets Blelloch and Wei
achieve wait-freedom in hazard pointer is that the combination
of publishing a guess and confirming that the guess is correct in hp_read
emulates an atomic memory-memory copy. Given such an atomic copy primitive, the read-side becomes trivial.
1 2 3 | |
The “only” problem is that atomic copies (which would look like locking all other cores out of memory accesses, copying the cell’s word-sized contents to record.pin, and releasing the lock) don’t exist in contemporary hardware.
However, we’ve already noted that syscalls like membarrier mean we can weaken our requirements to interrupt atomicity. In other words, individual non-atomic instructions work since we’re assuming precise interrupts… and x86 and amd64 do have an instruction for memory-memory copies!
The MOVS instructions are typically only used with a REP prefix. However, they can also be executed without any prefix, to execute one iteration of the copy loop. Executing a REP-free MOVSQ instruction copies one quadword (8 bytes) from the memory address in the source register [RSI] to the address in the destination register [RDI], and advances both registers by 8 bytes… and all this stuff happens in one instruction, so will never be split by an interrupt.
That’s an interrupt-atomic copy, which we can slot in place
of the software atomic copy in Blelloch and Wei’s proposal!
1 2 3 | |
Again, the MOVS instruction is not atomic, but will be ordered with
respect to the membarrier syscall in hp_cleanup_membarrier: either
the copy fully executes before the membarrier in C1, in which case the
pinned value will be visible to the cleanup loop, or it executes after
the membarrier, which guarantees the copy will not observe a stale value
that’s waiting in the limbo list.
That’s just one instruction, but instructions aren’t all created
equal. MOVS is on the heavy side: in order to read from memory, write to memory, and increment two registers,
a modern Intel chip has to execute 5 micro-ops in at least ~5 cycles.
That’s not exactly fast; definitely better than an atomic (LOCKed)
instruction, but not fast.
We can improve that with a trick from side-channel attacks, and
preserve wait-freedom. We can usually guess what value we’ll find in
record.pin, simply by reading cell with a regular relaxed load.
Unless we’re extremely unlucky (realistically, as long as the reader
thread isn’t interrupted), MOVSQ will copy the same value we just
guessed. That’s enough to exploit branch prediction and turn a data
dependency on MOVSQ (a high latency instruction) into a data
dependency on a regular load MOV (low latency), and a highly
predictable control dependency. In very low level pseudo code, this
“speculative” version of the MOVS read-side might look like:
1 2 3 4 5 6 | |
1 2 3 4 5 6 7 8 9 10 | |
We’ll see that, in reasonable circumstances, this wait-free
code sequence is faster than the usual membarrier-based lock-free
read side. But first, let’s see how we can achieve wait-freedom
when CISCy instructions like MOVSQ aren’t available, with an asymmetric “helping” scheme.
Interrupt-atomic copy, with some help
Blelloch and Wei’s wait-free atomic copy primitive builds on the usual
trick for wait-free algorithms: when a thread would wait for an
operation to complete, it helps that operation make progress instead
of blocking. In this specific case, a thread initiates an atomic copy
by acquiring a fresh hazard pointer record, setting that descriptor’s
pin field to \(\bot\), publishing the address it wants to
copy from, and then performing the actual copy. When another thread
enters the cleanup loop and wishes to read the record’s pin field , it may either find a value, or
\(\bot\); in the latter case, the cleanup thread has to help the
hazard pointer descriptor forward, by attempting to update the
descriptor’s pin field.
This strategy has the marked advantage of working. However, it’s also symmetric between the common case (the thread that initiated the operation quickly completes it), and the worst case (a cleanup thread notices the initiating thread got stuck and moves the operation along). This forces the common case to use atomic operations, similarly to the way cleanup threads would. We pessimised the common case in order to eliminate blocking in the worst case, a frequent and unfortunate pattern in wait-free algorithms.
The source of that symmetry is our specification of an atomic copy
from the source field to a single destination pin field, which must
be written exactly once by the thread that initiated the copy
(the hazard pointer reader), or any concurrent helper (the cleanup loop).
We can relax that requirement, since we know that the hazard pointer
scanning loop can handle spurious or garbage pinned values. Rather
than forcing both the read sequence (fast path) and the cleanup loop (slow path) to write to the same
pin field, we will give each HP record two pin fields: a
single-writer one for the fast path, and a multi-writer one for all
helpers (all threads in cleanup code).
The read-side sequence will have to first write to the HP record to publish the cell it’s reading from, read and publish the cell’s pinned value, and then check if a cleanup thread helped the record along. If the record was helped, the read-side sequence must use the value written by the helping cleanup thread. This means cleanup threads can detect when a HP record is missing its pinned value, and help it along with the cell’s current value. Cleanup threads may later observe two pinned values (both the reader and a cleanup thread wrote a pinned value); in that case, both values are conservatively protected from physical destruction.
Until now a hazard pointer record has only had one field, the “pinned” value. We must add some complexity to make this asymmetric helping scheme work: in order for cleanup threads to be able to help, we must publish the cell we are reading, and we need somewhere for cleanup threads to write the pinned value they read. We also need some sort of ABA protection to make sure slow cleanup threads don’t overwrite a fresher pinned value with a stale one, when the cleanup thread gets stuck (preempted).
Concretely, the HP record still has a pin field, which is only
written by the reader that owns the record, and read by cleanup
threads. The help subrecord is written by both the owner of the
record and any cleanup thread that might want to move a reader along. The
reader will first write the address of the pointer it wants to read
and protect in cell, generate a new unique generation id by incrementing
gen_sequence, and write that to pin_or_gen. We’ll tag
generation ids with their sign: negative
values are generation ids, positive ones are addresses.
1 2 3 4 5 6 7 8 9 10 | |
At this point, any cleanup thread should be able to notice that the
help.pin_or_gen is a generation value, and find a valid cell address
in help.cell. That’s all the information a cleanup threads needs to
attempt to help the record move forward. It can read the cell’s value, and publish
the pinned value it just read with an atomic compare-and-swap (CAS) of
pin_or_gen; if the CAS fails, another cleanup thread got there first, or
the reader has already moved on to a new target cell. In the latter
case, any in-flight hazard pointer read sequence started before we
started reclaiming the limbo list, and it doesn’t matter what pinned
value we extract from the record.
Having populated the help subrecord, a reader can now publish a
value in pin, and then look for a pinned value in
help.pin_or_gen: if a cleanup thread published a pinned value there, the
reader must use it, and not the potentially stale (already destroyed)
value the reader wrote to pin.
On the read side, we obtain plain wait-freedom, with standard operations.
All we need are two compiler barriers to let
membarriers guarantee writes to the help subrecord are visible
before we start reading from the target cell, and to guarantee
that any cleanup thread’s write to record.help.pin_or_gen is visible
before we compare record.help.pin_or_gen against gen:
1 2 3 4 5 6 7 8 9 10 11 12 | |
On the cleanup side, we will consume the limbo list, issue a
membarrier to catch any read-side critical section that wrote to
pin_or_gen before we consumed the list, help these sections
along, issue another membarrier to guarantee that either the readers’
writes to record.pin are visible, or our writes to
record.help.pin_or_gen are visible to readers, and finally scan the
records while remembering to pin the union of record.pin and
record.help.pin_or_gen if the latter holds a pinned value.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
The membarrier in C1 matches the compiler barrier in RA: if a
read-side section executed R2 before we consumed the limbo list, its
writes to record.help must be visible. The second membarrier in
C2 matches the compiler barrier in RB: if the read-side section
has written to record.pin, that write must be visible, otherwise,
the cleanup threads’s write to help.pin_or_gen must be visible to the reader.
Finally, when scanning for pinned values, we can’t determine whether
the reader used its own value or the one we published, so we must
conservatively add both to the pinned set.
That’s a couple more instructions on the read-side than the
speculative MOVSQ implementation. However, the instructions are
simpler, and the portable wait-free implementation benefits even more
from speculative execution: the final branch is equally predictable,
and now depends only on a read of record.help.pin_or_gen, which can
be satisfied by forwarding the reader’s own write to that same field.
The end result is that, in my microbenchmarks, this portable wait-free
implementation does slightly better than the speculative MOVSQ code.
We make this even tighter, by further specialising the code. The cleanup
path is already slow. What if we also assumed mutual exclusion; what if,
for each record, only one cleanup at a time could be in flight?
Interrupt-atomic copy, with at most one helper
Once we may assume mutual exclusion between cleanup loops–more specifically, the “help” loop, the only part that writes to records–we don’t have to worry about ABA protection anymore. Hazard pointer records can lose some weight.
1 2 3 4 5 6 | |
We’ll also use tagging with negative or positive values, this time to distinguish target cell addresses (positive) from pinned values (negative). Now that the read side doesn’t have to update a generation counter to obtain unique sequence values, it’s even simpler.
1 2 3 4 5 6 7 8 9 | |
The cleanup function isn’t particularly different, except for the new encoding scheme.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
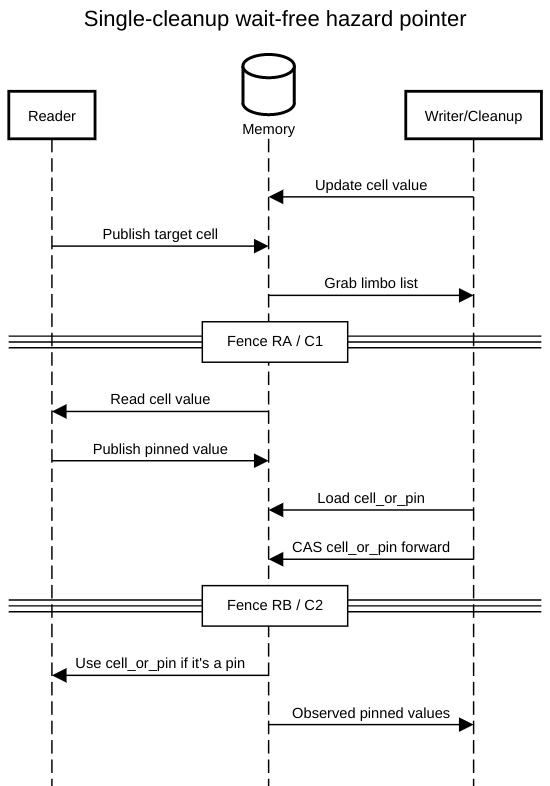
Again, RA matches C1, and RB C2. This new implementation is simpler than hp_read_wf on the read side, and needs even fewer instructions.
Qualitative differences between HP implementations
A key attribute for hazard pointers is how much they slow down pointer traversal in the common case. However, there are other qualitative factors that should impact our choice of implementation.
The classic fenced (hp_read_explicit) implementation
needs one atomic or fence instruction per read, but does not require any
exotic OS operation.
A simple membarrier implementation (hp_read_membarrier)
is ABI-compatible with the fenced implementations, but lets the read side
replace the fence with a compiler barrier, as long as the
slow cleanup path can issue membarrier syscalls
on Linux, or the similar FlushProcessWriteBuffers
on Windows. All the remaining implementations (we won’t mention the much more complex wait-free implementation of Blelloch and Wei)
also rely on the same syscalls to avoid fences or atomic instructions
on the read side, while additionally providing wait-freedom (constant
execution time) for readers, rather than mere lock-freedom.
The simple MOVSQ-based implementations (hp_read_movs) is fully
compatible with hp_read_membarrier, wait-free, and usually compiles
down to fewer instruction bytes, but is slightly slower. Adding
speculation (hp_read_movs_spec) retains compatibility and closes the
performance gap, with a number of instruction bytes comparable to the
lock-free membarrier implementation. In both cases, we rely on
MOVSQ, an instruction that only exists on x86 and amd64.
However, we can also provide portable wait-freedom, once we modify the
cleanup code to help the read side sections forward. The basic
implementation hp_read_wf compiles to many more instructions than
the other read-side implementations, but those instructions are mostly
upstream of the protected pointer read; in microbenchmarks, the result
can even be faster than the simple hp_read_membarrier or the
speculative hp_read_movs_spec. The downside is that instruction
bytes tend to hurt much more in real code than in microbenchmarks.
We also rely on pointer tagging, which could make the code less widely applicable.
We can simplify and shrink the portable wait-free code by assuming
mutual exclusion on the cleanup path (hp_read_swf). Performance is
improved or roughly the same, and instruction bytes comparable to
hp_read_membarrier. However, we’ve introduced more opportunities
for reclamation hiccups.
More importantly, achieving wait-freedom with concurrent help suffers
from a fundamental issue: helpers don’t know that the pointer read they’re
helping move forward is stale until they (fail to) CAS into
place the value they just read. This means they must be able to safely read potentially stale
pointers without crashing. One might think mutual exclusion in the
cleanup function fixes that, but programs often mix and match
different reclamation schemes, as well as lock-free and lock-ful code.
On Linux, we could
abuse the process_vm_readv syscall;13
in general I suppose we could install signal handlers to catch SIGSEGV and SIGBUS.
The stale read problem is even worse for the single-cleanup hp_read_swf read sequence:
there’s no ABA protection, so a cleanup helper can pin an
old value in record.help.cell_or_pin. This could happen if a
read-side sequence is initiated before hp_cleanup_swf’s membarrier
in C1, and the associated incomplete record is noticed by the
helper, at which point the helper is preempted. The read-side
sequence completes, and later uses the same record to read from the
same address… and that’s when the helper resumes execution, with a
compare_exchange that succeeds.
The pinned value “helped in” by hp_cleanup_swf is still valid—the
call to hp_cleanup_swf hasn’t physically destroyed anything yet—so
the hazard pointer implementation is technically correct. However,
this scenario shows that hp_read_swf can violate memory ordering and
causality, and even let long-overwritten values time travel into the future. The
simpler read-side code sequence comes at a cost: its load is extremely
relaxed, much more so than any intuitive mental model might allow.14
EDIT 2020-07-09: However, see this addendum for a way to fix that race without affecting the fast (read) path.
Having to help readers forward also loses a nice practical property of hazard pointers: it’s always safe to spuriously consider arbitrary (readable) memory as a hazard pointer record, it only costs us additional conservatism in reclamation. That’s not the case anymore, once the cleanup thread has to help readers, and thus must write to HP records. This downside does not impact plain implementations of hazard pointers, but does make it harder to improve record management overhead by taking inspiration from managed language runtimes.
Some microbenchmarks
The overhead of hazard pointers only matters in code that traverse a lot of pointers, especially pointer chains. That’s why I’ll focus on microbenchmarking a loop that traverses a pseudo-randomly shuffled circular linked list (embedded in an array of 1024 nodes, at 16 bytes per node) for a fixed number of pointer chasing hops. You can find the code to replicate the results in this gist.
The unprotected (baseline) inner loop follows. Note the NULL
end-of-list check, for realism; the list is circular, so the loop
never breaks early.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
There’s clearly a dependency chain between each read of head->next.
The call to frob_ptr lets us introduce work in the dependency chain,
which more closely represents realistic use cases. For example, when
using hazard pointers to protect a binary search tree traversal, we
must perform a small amount of work to determine whether we want to go
down the left or the right subtree.
A hazard pointer-ed implementation of this loop would probably unroll the loop body twice, to more easily implement hand-over-hand locking. That’s why I also include an unrolled version of this inner loop in the microbenchmark: we avoid discovering that hazard pointer protection improves performance because it’s also associated with unrolling, and gives us an idea of how much variation we can expect from small code generation changes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
The hazard pointer inner loops are just like the above, except that
head = head->next is replaced with calls to an inline function.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
The dependency chain is pretty obvious; we can measure the sum of latencies for 1000 pointer dereferences by running the loop 1000 times. I’m using a large iteration count to absorb noise from the timing harness (roughly 50 cycles per call), as well as any boundary effect around the first and last few loop iterations.
All the cycle measurements here are from my unloaded E5-4617, running
at 2.9 GHz without Turbo Boost. First, let’s see what happens with a
pure traversal, where frob_ptr is an inline no-op function
that simply return its first argument. This microbenchmark is far
from realistic (if I found an inner loop that only traversed a
singly linked list, I’d consider a different data structure), but helps
establish an upper bound on the overhead from different hazard pointer
read sides. I would usually show a faceted graph of the latency
distribution for the various methods… but the results are so stable15
that I doubt there’s any additional information to be found in the graphs,
compared to the tables below.
The following table shows the cycle counts for following 1000 pointers in a circular linked list, with various hazard pointer schemes and no work to find the next node, on an unloaded E5-4617 @ 2.9 GHz, without Turbo Boost.
| Method * 1000 iterations | p00.1 latency | median latency | p99.9 latency |
|---------------------------|---------------|----------------|---------------|
| noop | 52 | 56 | 56 |
| baseline | 4056 | 4060 | 4080 |
| unrolled | 4056 | 4060 | 4080 |
| hp_read_explicit | 20136 | 20160 | 24740 |
| hp_read_membarrier | 5080 | 5092 | 5164 |
| hp_read_movs | 10060 | 10076 | 10348 |
| hp_read_movs_spec | 8568 | 8568 | 8572 |
| hp_read_wf | 6572 | 7620 | 8140 |
| hp_read_swf | 4268 | 4304 | 4368 |
The table above reports quantiles for the total runtime of 1000 pointer dereferences, after one million repetitions.
We’re looking at a baseline of 4 cycles/pointer dereference (the L1 cache
latency), regardless of unrolling. The only implementation with an
actual fence or atomic operation, hp_read_explicit fares pretty
badly, at more than 5x the latency. Replacing that fence with a
compiler barrier in hp_read_membarrier reduces the overhead to ~1
cycle per pointer dereference. Our first wait-free implementation,
hp_read_movs (based on a raw MOVSQ) doesn’t do too great, with a
~6 cycle (150%) overhead for each pointer dereference. However,
speculation (hp_read_movs_spec) does help shave that to ~4.5 cycles
(110%). The portable wait-free implementation hp_read_wf does
slightly better, and its single-cleanup version hp_read_swf takes
the crown, by adding around 0.2 cycle/dereference.
These results are stable and repeatable, but still fragile, in a way:
except for hp_read_explicit, which is massively slowed down by its
atomic operation, and for hp_read_movs, which adds a known latency bump on the hot path, the other slowdowns mostly reflect contention for
execution resources. In real life, such contention usually only occurs in
heavily tuned code, and the actual execution units (ports) in high
demand will vary from one inner loop to another.
Let’s see what happens when we insert a ~4-cycle latency slowdown
(three for the multiplication, and one more for the increment) in the
hot path, by redefining frob_ptr. The result of the integer
multiplication by 0 is always 0, but adds a (non speculated) data
dependency on the node value and on the multiplication to the pointer
chasing dependency chain. Only four cycles of work to decide which
pointer to traverse is on the low end of my practical experience, but
suffices to equalise away most of the difference between the hazard
pointer implementations.
1 2 3 4 5 6 7 8 9 | |
Let’s again look at the quantiles for the cycle count for one million loops of 1000 pointer dereferences, on an unloaded E5-4617 @ 2.9 GHz.
| Method * 1000 iterations | p00.1 latency | median latency | p99.9 latency |
|---------------------------|---------------|----------------|---------------|
| noop | 52 | 56 | 56 |
| baseline | 10260 | 10320 | 10572 |
| unrolled | 9056 | 9060 | 9180 |
| hp_read_explicit | 22124 | 22156 | 26768 |
| hp_read_membarrier | 10052 | 10084 | 10264 |
| hp_read_movs | 12084 | 12112 | 15896 |
| hp_read_movs_spec | 9888 | 9940 | 10152 |
| hp_read_wf | 9380 | 9420 | 9672 |
| hp_read_swf | 10112 | 10136 | 10360 |
The difference between unrolled in this table and in the previous
one shows we actually added around 5 cycles of latency per iteration
with the multiplication in frob_ptr. This dominates the overhead we
estimated earlier for all the hazard pointer schemes except for the
remarkably slow hp_read_explicit and hp_read_movs. It’s thus not
surprising that all hazard pointer implementations but the latter
two are on par with the unprotected traversal loops (within 1.1 cycle
per pointer dereference, less than the impact of unrolling the loop
without unlocking any further rewrite).
The relative speed of the methods has changed, compared
to the previous table. The speculative wait-free implementation
hp_read_movs_spec was slower than hp_read_membarrier and much
slower than hp_read_swf; it’s now slightly faster than both.
The simple portable wait-free implementation hp_read_wf was slower than
hp_read_membarrier and hp_read_swf; it’s now the fastest implementation.
I wouldn’t read too much into the relative rankings of
hp_read_membarrier, hp_read_movs_spec, hp_read_wf, and
hp_read_swf. They only differ by fractions of a cycle per
dereference (all between 9.5 and 10.1 cycle/deref), and the exact values are a function of the
specific mix of micro-ops in the inner loop, and of the
near-unpredictable impact of instruction ordering on the chip’s
scheduling logic. What really matters is that their impact
on traversal latency is negligible once the pointer chasing loop does some
work to find the next node.
What’s the best hazard pointer implementation?
I hope I’ve made a convincing case that hazard pointers can be
wait-free and efficient on the read-side, as long as we have access
to something like membarrier or FlushProcessWriteBuffers on the
slow cleanup (reclamation) path. If one were to look at the
microbenchmarks alone, one would probably pick hp_read_swf.
However, the real world is more complex than microbenchmarks. When I
have to extrapolate from microbenchmarks, I usually worry about the
hidden impact of instruction bytes or cold branches, since
microbenchmarks tend to fail at surfacing these things. I’m not as
worried for hp_read_movs_spec, and hp_read_swf: they both compile
down to roughly as many instructions as the incumbent, hp_read_membarrier,
and their forward untaken branch would be handled fine by a static predictor.
What I would take into account is the ability to transparently use
hp_read_movs_spec in code that already uses hp_read_membarrier,
and the added requirements of hp_read_swf. In
addition to relying on membarrier for correctness, hp_read_swf
needs a pointer tagging scheme to distinguish target pointers from pinned ones, a way for cleanup threads to read stale pointers without
crashing, and also imposes mutual exclusion around the scanning of (sets
of) hazard pointer records. These additional requirements don’t seem
impractical, but I can imagine code bases where they would constitute
hard blockers (e.g., library code, or when protecting arbitrary integers).
Finally, hp_read_swf can let protected values time travel in the future,
with read sequences returning values so long after they were overwritten
that the result violates pretty much any memory ordering model… unless
you implement the addendum below.
TL;DR: Use hp_read_swf if you’re willing to sacrifice wait-freedom on the reclamation path and remember to implement the cleanup function with time travel protection. When targeting x86 and amd64, hp_read_movs_spec is a well rounded option, and still wait-free. Otherwise, hp_read_wf uses standard operations, but compiles down to more code.
P.S., Travis Downs notes that mem-mem PUSH might be an alternative to MOVSQ, but that requires either pointing RSP to arbitrary memory, or allocating hazard pointers on the stack (which isn’t necessarily a bad idea). Another idea worthy of investigation!
Thank you, Travis, for deciphering and validating a much rougher draft when the preprint dropped, and Paul and Jacob, for helping me clarify this last iteration.
Addendum 2020-07-09: fix time travel in hp_read_swf
There is one huge practical issue with
hp_read_swf, our simple and wait-free hazard pointer read sequence
that sacrifices lock-free reclamation to avoid x86-specific instructions:
when the cleanup loop must help a record forward, it can fill in old values in ways that violate causality.
I noted that the reason for this hole is the lack of ABA protection in
HP records… and hp_read_wf is what we’d get if we were to add full ABA protection.
However, given mutual exclusion around the “help” loop in the cleanup
function, we don’t need full ABA protection. What we really need to
know is whether a given in-flight record we’re about to CAS forward is
the same in-flight record for which we read the cell’s value, or was
overwritten by a read-side section. We can encode that by
stealing one more bit from the target cell address in cell_or_pin.
We already steal the sign bit to distinguish the address of the cell
to read (positive), from pinned values (negative). The split make
sense because 64 bit architectures tend to reserve high (negative)
addresses for kernel space. I doubt we’ll see full 64 bit address
spaces for a while, so it seems safe to steal the next bit (bit 62) to
tag cell addresses. The next table summarises the tagging scheme.
0b00xxxx: untagged cell address
0b01xxxx: tagged cell address
0b1yyyyy: helped pinned value
At a high level, we’ll change the hp_cleanup_swf to tag
cell_or_pin before reading the value pointed by cell, and only CAS in the
new pinned value if the cell is still tagged.
Thanks to mutual exclusion, we know cell_or_pin can’t be re-tagged by another thread.
Only the for record in records block has to change.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
We doubled the number of atomic operations in the helping loop, but
that’s acceptable on the slow path. We also rely on strong
compare_exchange (compare-and-swap) acting as a store-load fence.
If that doesn’t come for free, we could also tag records in one pass,
issue a store-load fence, and help tagged records in a
second pass.
Another practical issue with the swf/wf cleanup approach is that
they require two membarriers, and
OS-provided implementations can be slow, especially under load.
This is particularly important for the swf approach, since mutual
exclusion means that one slow membarrier delays the physical destruction of everything on the limbo list.
I don’t think we can get rid of mutual exclusion, and, while we can improve membarrier latency, reducing the number of membarriers on the reclamation path is always good.
We can software pipeline calls to the cleanup function,
and use the same membarrier for C1 and C2 in two consecutive
cleanup calls. Overlapping cleanups decreases the worst-case reclaim
latency from 4 membarriers to 3, and that’s not negligible when each
membarrier can block for 30ms.
-
I also tend to read anything by Guy Blelloch. ↩
-
In fact, I’ve often argued that SMR is garbage collection, just not fully tracing GC. Hazard pointers in particular look a lot like deferred reference counting, a form of tracing GC. ↩
-
Something that wasn’t necessarily obvious until then. See, for example, this article presented at PPoPP 2020, which conjectures that “making the original Hazard Pointers scheme or epoch-based reclamation completely wait-free seems infeasible;” Blelloch was in attendance, so this must have been a fun session. ↩
-
The SMR problem is essentially the same problem as determining when it’s safe to return from
rcu_synchronizeor execute arcu_callcallback. Hence, the same reader-writer lock analogy holds. ↩ -
Hazard pointer records must still be managed separately, e.g., with a type stable allocator, but we can bootstrap everything else once we have a few records per thread. ↩
-
We can even do that without keeping track of the number of nodes that were previously pinned by hazard pointer records and kept in the limbo list: each record can only pin at most one node, so we can wait until the limbo list is, e.g., twice the size of the record set. ↩
-
Let’s also hope efforts like CHERI don’t have to break lock-free code. ↩
-
The scheme is correct with any actual guess; we could even use a random number generator. However, performance is ideal (the loop exits) when we “guess” by reading current value of the pointer we want to borrow safely. ↩
-
I tend to implement lock-free algorithms with a heavy dose of inline assembly, or Concurrency Kit’s wrappers: it’s far too easy to run into subtle undefined behaviour. For example, comparing a pointer after it has been freed is UB in C and C++, even if we don’t access the pointee. Even if we compare as
uintptr_t, it’s apparently debatable whether the code is well defined when the comparison happens to succeed because the pointee was freed, then recycled in an allocation and published tocellagain. ↩ -
In Reclaiming Memory for Lock-Free Data Structures: There has to be a Better Way, Trevor Brown argues this requirement is a serious flaw in all hazard pointer schemes. I think it mostly means applications should be careful to coarsen the definition of resource in order to ensure the resulting condensed heap graph is a DAG. In extreme cases, we end up proxy collecting an epoch, but we can usually do much better. ↩
-
That’s what Travis Downs classifies as a Level 1 concurrency cost, which is usually fine for writes, but adds a sizable overhead to simple read-only code. ↩
-
I suppose this means the reclamation path isn’t wait-free, or even lock-free, anymore, in the strict sense of the words. In practice, we’re simply waiting for periodic events that would occur regardless of the syscalls we issue. People who really know what they’re doing might have fully isolated cores. If they do, they most likely have a watchdog on their isolated and latency-sensitive tasks, so we can still rely on running some code periodically, potentially after some instrumentation: if an isolated task fails to check in for a short while, the whole box will probably be presumed wedged and taken offline. ↩
-
With the caveat that the public documentation for
process_vm_readvdoes not mention any atomic load guarantee. In practice, I saw a long-by-long copy loop the last time I looked at the code, and I’m pretty sure the kernel’s build flags prevent GCC/clang from converting it tomemcpy. We could rely on the strong “don’t break userspace” culture, but it’s probably a better idea to try and get that guarantee in writing. ↩ -
This problem feels like something we could address with a coarse epoch-based versioning scheme. It’s however not clear to me that the result would be much simpler than
hp_read_wf, and we’d have to steal even more bits (2 bits, I expect) fromcell_or_pinto make room for the epoch. EDIT 2020-07-09: it turns out we only need to steal one bit. ↩ -
Although I did compare several independent executions and confirmed the reported cycle counts were stable, I did not try to randomise code generation… mostly because I’m not looking for super fine differences as much as close enough runtimes. Hopefully, aligning functions to 256 bytes leveled some bias away. ↩