Xecto, a new project - the plumbing
Xecto is another (SBCL-only) project of mine, available in its very preliminary state on github. It started out as a library for regular parallel operations on arrays (reduce, scan, map, etc), with the goal, not of hitting as close to peak performance as possible through whatever trick necessary, but rather to have a simple execution model, and thus a simple performance model as well. These days, I’d rather have a tool that can’t hit the theoretical peak performance, but has a simple enough performance model that I can program close to the tool’s peak, than a tool that usually gives me excellent performance through ill-explained voodoo (and sometimes suffers from performance glass jaw issues).
I like to think of it as preferring to map operations to the BLAS instead of writing loops in C and hoping the compiler autovectorise everything correctly. When performance is really critical, smart people can study the problem and come up with a judicious mixture of high-level optimisations, specialised code generators and hand-rolled assembly (ATLAS, GotoBLAS, FFTW, MKL, etc). When performance isn’t that important, going for a tool that’s easy to understand at the expense of some runtime performance (e.g. by punting to more generic but heavily optimised libraries from the previous list) is probably a good engineering trade-off. It seems to me it’s only in a strange no man’s land of applications that must really run quickly, but don’t justify the development of a bespoke solution, that complex automagic optimisation shines.
Xecto represents the nth time I’ve written most of the components: work queues, task-stealing deques, futures, optimising simple array-processing loops, etc. I’m very aggressively fighting the second system effect, and going for a simple, often simplistic, design. My hope is that this will yield a robust parallel-processing library upon which others can build as well.
I’ll try to document the state of the project as it goes. There’s currently a basic working prototype: parallel processing infrastructure, arrays as vectors and shape metadata, a minimal loop nest optimiser, and parallel (task, data and SIMD) execution of vector operations. I’m now trying to go from prototype to useful code.
Note that Xecto is SBCL-only: I use atomic primitives a lot, and don’t care that much about portability (yet).
1 Parallel processing plumbing
The base of the parallelisation infrastructure is a thread pool; spawning one thread for each task is a silly waste of resources and often leads to CPUs constantly switching context between threads.
The thread pool (thread-pool.lisp) spawns a fixed number of worker threads
ahead of time, and jobs are submitted via a queue of work units. A job can simply be
a function or a symbol to call, but that’s not very useful: we usually want to know
when the job is finished and what the result was.
A task structure (work-units.lisp) can be used for that. The function slot of
the structure will be called, with the task as its single argument. With inheritance,
we can add a slot to hold the result, and another to wait for status changes
(status.lisp). status.lisp implements a simple way to wait on a status, optimised
for the common case when tasks are completed before the program waits on them: a
status slot usually only stores status symbols, but waiters upgrade it to
a reference to a structure with a mutex/waitqueue pair for more efficient
waiting.
We often have a large number of small independent work units that represent a
larger, logical, work units. A bulk task structure (work-units.lisp) implements that
case. A vector of subtasks is provided, and a function is called for each subtask; when
all the subtasks have finished executing, a cleanup function is called. In the case of
vector processing (and in many others), there is a certain locality between adjacent
work units. The work queue exploits that by allowing multiple threads to work on the
same bulk task, but ensuring that each thread tends to only execute its own range of
subtasks.
Work units also often recursively generate additional work units. They could
simply go through the regular work unit queue. In practice, however, it’s much more
interesting to skip that and execute them on the same worker, in stack order
(work-stack.lisp). We avoid some synchronisation overhead, and the LIFO
evaluation order tends to improve temporal locality. If there were only private
evaluation stacks, we could easily find ourselves with a lot of available tasks, but all
assigned to a few workers. That’s why tasks can be stolen by idle workers when the
queue is empty.
Finally, tasks also have dependencies: we want to only start executing a given task after all its dependencies have completed their own execution.
The thread pool supports recursive waiting: work units can wait for other work units to complete. The worker thread will then continue executing tasks (on its stack first, then from the shared queue or by stealing) until the criterion (all dependencies fully executed) is met. This can waste a lot of stack space compared to implementations like Cilk that can steal and release waiting stack frames when the dependencies have all executed. However, the implementation is simple, and the space overhead is reasonable: a quadratic increase, in the worst case, I believe. If the serial program’s stack usage is decent (e.g. polylogarithmic in the input), it shouldn’t be an issue.
There’s also some machinery to move the dependency logic in the thread pool and
eliminate the disadvantages of recursive waiting. Dependencies are registered between
futures (futures.lisp, parallel-futures.lisp), and, when a future’s last
dependency has just finished executing, it’s marked for execution (on the current
worker’s stack). Because of my needs for vector processing, futures are bulk tasks
with a function that’s called before executing the subtasks, and anoter one
after.
It’s nothing special, and a lot of things is clearly suboptimal, but it’s mostly decent and can be improved again later.
2 General-purpose parallel processing primitives
The code that I mention in the previous section is already sufficient for a few
common parallel processing primitives (parallel-primitives.lisp). Xecto doesn’t
use them, but they’re still pretty useful.
2.1 Promises, parallel:let
These are simple tasks that are always pushed on the worker’s stack if possible, or on the current parallel execution context otherwise.
parallel:promise takes a function and a list of arguments, and pushes/enqueues
a task that call the function with these arguments, and saves the results.
parallel:promise-value will wait for the promise’s value, while
parallel:promise-value* will recursively wait on chains of promises.
parallel:let uses promises to implement something like Qlisp’s qlet. The
syntax is the same as let (except for bindings without value forms), and the bound
values are computed in parallel. A binding clause for :parallel defines a predicate
value: if the value is true, the clauses are evaluated in parallel (the default), otherwise
it’s normal serial execution.
This, along with the fact that waiting in workers doesn’t stop parallel execution, means that we can easily parallelise a recursive procedure like quicksort.
All of the following code is a normal quicksort.
(deftype index ()
‘(mod ,most-positive-fixnum))
(declaim (inline selection-sort partition find-pivot))
(defun partition (vec begin end pivot)
(declare (type (simple-array fixnum 1) vec)
(type index begin end)
(type fixnum pivot)
(optimize speed))
(loop while (> end begin)
do (if (<= (aref vec begin) pivot)
(incf begin)
(rotatef (aref vec begin)
(aref vec (decf end))))
finally (return begin)))
(defun selection-sort (vec begin end)
(declare (type (simple-array fixnum 1) vec)
(type index begin end)
(optimize speed))
(loop for dst from begin below end
do
(let ((min (aref vec dst))
(min-i dst))
(declare (type fixnum min)
(type index min-i))
(loop for i from (1+ dst) below end
do (let ((x (aref vec i)))
(when (< x min)
(setf min x
min-i i))))
(rotatef (aref vec dst) (aref vec min-i)))))
(defun find-pivot (vec begin end)
(declare (type (simple-array fixnum 1) vec)
(type index begin end)
(optimize speed))
(let ((first (aref vec begin))
(last (aref vec (1- end)))
(middle (aref vec (truncate (+ begin end) 2))))
(declare (type fixnum first last middle))
(when (> first last)
(rotatef first last))
(cond ((< middle first)
first
(setf middle first))
((> middle last)
last)
(t
middle))))
Here, the only difference is that the recursive calls happen via parallel:let.
(defun pqsort (vec)
(declare (type (simple-array fixnum 1) vec)
(optimize speed))
(labels ((rec (begin end)
(declare (type index begin end))
(when (<= (- end begin) 8)
(return-from rec (selection-sort vec begin end)))
(let* ((pivot (find-pivot vec begin end))
(split (partition vec begin end pivot)))
(declare (type fixnum pivot)
(type index split))
(cond ((= split begin)
(let ((next (position pivot vec
:start begin
:end end
:test-not #’eql)))
(assert (> next begin))
(rec next end)))
((= split end)
(let ((last (position pivot vec
:start begin
:end end
:from-end t
:test-not #’eql)))
(assert last)
(rec begin last)))
(t
(parallel:let ((left (rec begin split))
(right (rec split end))
(:parallel (>= (- end begin) 512)))
(declare (ignore left right))))))))
(rec 0 (length vec))
vec))
We will observe that, mostly thanks to the coarse grain of parallel recursion (only for inputs of size 512 or more), the overhead compared to the serial version is tiny.
We can test the performance (and scaling) on random vectors of fixnums. I also compared with SBCL’s heapsort to make sure the constant factors were decent, but the only reasonable conclusion seems to be that our heapsort is atrocious on largish vectors.
(defun shuffle (vector)
(declare (type vector vector))
(let ((end (length vector)))
(loop for i from (- end 1) downto 0
do (rotatef (aref vector i)
(aref vector (random (+ i 1)))))
vector))
(defun test-pqsort (nproc size)
(let ((vec (shuffle (let ((i 0))
(map-into (make-array size
:element-type ’fixnum)
(lambda ()
(incf i)))))))
(parallel-future:with-context (nproc) ; create an independent thread
(time (pqsort vec))) ; pool
(loop for i below (1- (length vec))
do (assert (<= (aref vec i) (aref vec (1+ i)))))))
Without parallelism (:parallel is nil), we find
* (test-pqsort 1 (ash 1 25)) Evaluation took: 6.245 seconds of real time 6.236389 seconds of total run time (6.236389 user, 0.000000 system) 99.86% CPU 17,440,707,947 processor cycles 0 bytes consed
With the parallel clause above, we instead have
* (test-pqsort 1 (ash 1 25)) Evaluation took: 6.420 seconds of real time 6.416401 seconds of total run time (6.416401 user, 0.000000 system) 99.94% CPU 17,930,818,675 processor cycles 45,655,456 bytes consed
All that parallel processing bookkeeping and additional indirection conses up 45 MB, but the net effect on computation time is negligible. Better: on my workstation, I observe nearly linear scaling until 4-5 threads, and there is still some acceleration by going to 8 or even 11 threads.
2.2 Futures
These are very similar to the futures I described above: they are created
(parallel:future) with a vector of dependencies, a callback, and, optionally, a
vector of subtasks (each subtask is a function to call) and a cleanup function.
parallel:future-value[*] will wait until the future has finished executing, and
the * variant recursively forces chains of futures.
parallel:bind binds, similarly to let, variables to the value of future values (if
not a future, the value is used directly), but waits by going through the work queue.
When the first form in the body is :wait, the macro waits for the body to finish
executing; otherwise, the future is returned directly.
These aren’t very useful directly, but are needed for parallel dotimes.
2.3 parallel:dotimes
Again, the syntax for parallel:dotimes is very similar to that of dotimes. The only
difference is the lack of implicit block and tagbody: the implicit block doesn’t make
sense in a parallel setting, and I was too lazy for tagbody (but it could easily be
added).
The body will be executed for each integer from 0 below the count value. There’s no need to adapt the iteration count to the number of threads: the macro generates code to make sure the number of subtasks is at most the square of the worker count, and the thread pool ensures that adjacent subtasks tend to be executed by the same worker. When all the iterations have been executed, the result value is computed, again by a worker thread (which allows, e.g., pushing work units recursively).
Again, when the first form in the body is :wait, the macro inserts code to wait
for the future’s completion; otherwise, the future is returned directly.
In other words, this macro implements a parallel for:
(parallel:dotimes (i (length vector) vector) :wait (setf (aref vector i) (f i)))
2.4 map, reduce, etc.
Given parallel:dotimes, it’s easy to implement parallel:map, parallel:reduce
and parallel:map-group-reduce (it’s something like map-reduce).
These are higher-order functions, and can waste a lot of performance executing generic code; inline them (or ask for high speed/low-space optimisation) to avoid that.
2.4.1 parallel:map
(parallel:map type function sequence &key (wait t)) coerces the argument
sequence to a simple vector, and uses parallel:dotimes to call the function on each
value. If type is nil, it’s only executed for effect, otherwise the result is stored in a
temporary simple vector and coerced to the right type. If wait, the value is returned,
otherwise a future is returned.
2.4.2 parallel:reduce
(parallel:reduce function sequence seed &key (wait t) key) agains coerces
to a simple vector and then does it via parallel:dotimes. It also exploits the
work-queue:worker-id to perform most of the reduction in thread-local
accumulators, only merging them at the very end. function should be associative
and commutatiev, and seed a neutral element for the function. key, if provided,
implements a fused map/reduce step. Again, wait determines whether the reduced
value or a future is returned.
2.4.3 parallel:map-group-reduce
parallel:map-group-reduce implements a hash-based map/group-by/reduce, or
closer to google’s map/reduce, a mapcan/group-by/reduce. Again, it is implemented
with thread-local accumulators and parallel:dotimes.
(map-group-reduce sequence map reduce &key group-test group-by) maps
over the sequence to compute a mapped value and a group-by value. The latter is the
map function’s second return value if group-by is nil, and group-by’s value for the
current input otherwise. All the values given the same (according to group-test)
group-by keys are reduced with the reduce function, and, finally, a vector of conses is
returned: the car are the group-by values, and the cdr the associated reduced
values.
When &key master-table is true, a hash table with the same associations is
returned as a second value, and when it’s instead :quick, a simpler to compute
version of that table is returned (the value associated with each key is a cons, as in
the primary return value).
When &key fancy is true, we have something more like the original map/reduce.
map is passed a value to process and a binary function: the first argument is the
group-by key, and the second the value.
The function can be used, for instance, to process records in a vector.
(parallel-future:with-context (4)
(parallel:map-group-reduce rows #’row-age #’+
:group-by #’row-first-name
:group-test #’equal))
=> #(("Bob" . 40) ("Alice" . 35) ...)
This uses up to four threads to sum the age of rows for each first name,
comparing them with equal.
A more classic example, counting the occurrences of words in a set of documents,
would use the :fancy interface and look like:
(defun count-words (documents)
(parallel:map-group-reduce documents
(lambda (document accumulator)
(map nil (lambda (word)
(funcall accumulator word 1))
document))
#’+
:group-test #’equal
:fancy t))
2.5 Multiple-producer single-consumer queue
mpsc-queue.lisp is a very simple (56 LOC) lock-free queue for multiple producers (enqueuers), but only a single consumer (dequeuer). It’s a really classic construction that takes a lock-free stack and reverses it from time to time to pop items in queue order. This (building a queue from stacks) must be one of the very few uses for those CS trick questions hiring committees seem to adore.
It’s not related at all to the rest of Xecto, but it’s cute.
3 Next
I think the next step will be generating the vector-processing inner loops in C, and
selecting the most appropriate one to use. Once that’s working, the arrays could be
extended to more types than just double-float, and allocated on the foreign
heap.
In the meantime, I hope the parallel primitives can already be useful. Please have some fun and enjoy the fruits of Nikodemus’s work on threads in SBCL.
P.S. The organisation of the code probably looks a bit weird. I’m trying
something out: a fairly large number of tiny internal packages that aren’t meant to be
:used.
posted at: 02:10 | /Lisp/Xecto | permalink
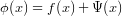
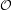
 ), where k is the number of iterations.
), where k is the number of iterations.
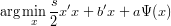
 x
x x
x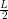
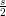 x
x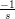 b.
b.
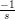 b (that’s actually true for any Ψ that represents
contraints). For the non-negative orthant, we only have to clamp each negative
component of
b (that’s actually true for any Ψ that represents
contraints). For the non-negative orthant, we only have to clamp each negative
component of 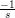 b to 0:
b to 0:
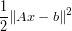
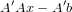
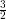 an intermediate value (usual case). The
relative values were similar with implementations in SBCL, both on a X5660 and on
a Core 2.
an intermediate value (usual case). The
relative values were similar with implementations in SBCL, both on a X5660 and on
a Core 2.