EDIT: Lutz Euler points out that the NEXT sequence (used to) encode
an effective address with an index register but no base. The mistake
doesn’t affect the meaning of the instruction, but forces a wasteful
encoding. The difference in machine code are as follows.
I fixed the definition of NEXT, but not the disassembly snippets
below; they still show the old machine code.
Earlier this week, I took another look at the
F18. As usual with Chuck Moore’s
work, it’s hard to tell the difference between insanity and mere
brilliance ;) One thing that struck me is how small the stack is: 10
slots, with no fancy overflow/underflow trap. The rationale is that,
if you need more slots, you’re doing it wrong, and that silent
overflow is useful when you know what you’re doing. That certainly
jibes with my experience on the HP-41C and with x87. It also reminds
me of a
post of djb’s decrying our misuse of x87’s rotating stack:
his thesis was that, with careful scheduling, a “free” FXCH makes
the stack equivalent – if not superior – to registers. The post
ends with a (non-pipelined) loop that wastes no cycle on shuffling
data, thanks to the x87’s implicit stack rotation.
That lead me to wonder what implementation techniques become available
for stack-based VMs that restrict their stack to, e.g., 8 slots.
Obviously, it would be ideal to keep everything in registers.
However, if we do that naïvely, push and pop become a lot more
complicated; there’s a reason why Forth engines usually cache only the
top 1-2 elements of the stack.
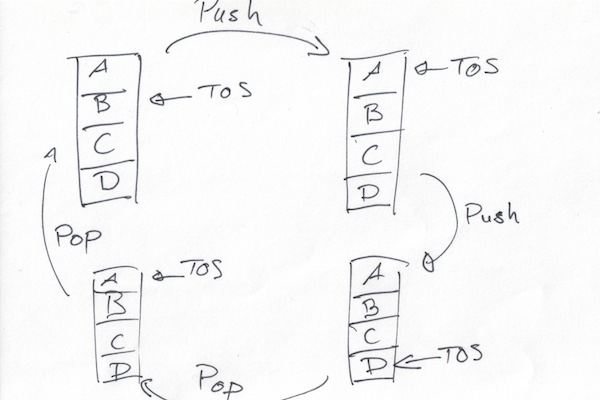
I decided to mimic the x87 and the F18 (EDIT: modulo the latter’s two
TOS cache registers): pushing/popping doesn’t cause any data movement.
Instead, like the drawing below shows, they decrement/increment a modular
counter that points to the top of the stack (TOS). That would still be
slow in software (most ISAs can’t index registers). The key is that
the counter can’t take too many values: only 8 values if there are 8
slots in the stack. Stack VMs already duplicate primops for performance
reasons (e.g., to help the BTB by spreading out execution of the same
primitive between multiple addresses), so it seems reasonable to specialise
primitives for all 8 values the stack counter can take.
In a regular direct threaded VM, most primops would end with a code
sequence that jumps to the next one (NEXT), something like
add rsi, 8 ; increment virtual IP before jumping
jmp [rsi-8] ; jump to the address RSI previously pointed to
where rsi is the virtual instruction pointer, and VM instructions
are simply pointers to the machine code for the relevant primitive.
I’ll make two changes to this sequence. I don’t like hardcoding
addresses in bytecode, and 64 bits per virtual instruction is overly
wasteful. Instead, I’ll encode offsets from the primop code block:
mov eax, [rsi]
add rsi, 4
add rax, rdi
jmp rax
where rdi is the base address for primops.
I also need to dispatch based on the new value of the implicit stack
counter. I decided to make the dispatch as easy as possible by
storing the variants of each primop at regular intervals (e.g. one
page). I rounded that up to 64 * 67 = 4288 bytes to minimise
aliasing accidents. NEXT becomes something like
mov eax, [rsi]
add rsi, 4
lea rax, [rax + rdi + variant_offset]
jmp rax
The trick is that variant_offset = 4288 * stack_counter, and the
stack counter is (usually) known when the primitive is compiled. If
the stack is left as is, so is the counter; pushing a value decrements
the counter and popping one increments it.
That seems reasonable enough. Let’s see if we can make it work.
Preliminaries
I want to explore a problem for which I’ll emit a lot of repetitive
machine code. SLIME’s REPL and SBCL’s assembler are perfect for the
task! (I hope it’s clear that I’m using unsupported internals; if it
breaks, you keep the pieces.)
The basic design of the VM is:
r8-r15: stack slots (32 bits);
rsi: base address for machine code primitives;
rdi: virtual instruction pointer (points to the next instruction);
(import '(sb-assem:inst sb-vm::make-ea)) ; we'll use these two a lot
;; The backing store for our stack
(defvar *stack* (make-array 8 :initial-contents (list sb-vm::r8d-tn
sb-vm::r9d-tn
sb-vm::r10d-tn
sb-vm::r11d-tn
sb-vm::r12d-tn
sb-vm::r13d-tn
sb-vm::r14d-tn
sb-vm::r15d-tn)))
;; The _primop-generation-time_ stack pointer
(defvar *stack-pointer*)
;; (@ 0) returns the (current) register for TOS, (@ 1) returns
;; the one just below, etc.
(defun @ (i)
(aref *stack* (mod (+ i *stack-pointer*) (length *stack*))))
(defvar *code-base* sb-vm::rsi-tn)
(defvar *virtual-ip* sb-vm::rdi-tn)
(defvar *rax* sb-vm::rax-tn)
(defvar *rbx* sb-vm::rax-tn)
(defvar *rcx* sb-vm::rax-tn)
(defvar *rdx* sb-vm::rax-tn)
;; Variants are *primitive-code-offset* bytes apart
(defvar *primitive-code-offset* (* 64 67))
;; Each *stack-pointer* value gets its own code page
(defstruct code-page
(alloc 0) ; index of the next free byte.
(code (make-array *primitive-code-offset* :element-type '(unsigned-byte 8))))
The idea is that we’ll define functions to emit assembly code for each
primitive; these functions will be implicitly parameterised on
*stack-pointer* thanks to @. We can then call them as many times
as needed to cover all values of *stack-pointer*. The only
complication is that code sequences will differ in length, so we must
insert padding to keep everything in sync. That’s what emit-code
does:
(defun emit-code (pages emitter)
;; there must be as many code pages as there are stack slots
(assert (= (length *stack*) (length pages)))
;; find the rightmost starting point, and align to 16 bytes
(let* ((alloc (logandc2 (+ 15 (reduce #'max pages :key #'code-page-alloc))
15))
(bytes (loop for i below (length pages)
for page = (elt pages i)
collect (let ((segment (sb-assem:make-segment))
(*stack-pointer* i))
;; assemble the variant for this value
;; of *stack-pointer* in a fresh code
;; segment
(sb-assem:assemble (segment)
;; but first, insert padding
(sb-vm::emit-long-nop segment (- alloc (code-page-alloc page)))
(funcall emitter))
;; tidy up any backreference
(sb-assem:finalize-segment segment)
;; then get the (position-independent) machine
;; code as a vector of bytes
(sb-assem:segment-contents-as-vector segment)))))
;; finally, copy each machine code sequence to the right code page
(map nil (lambda (page bytes)
(let ((alloc (code-page-alloc page)))
(replace (code-page-code page) bytes :start1 alloc)
(assert (<= (+ alloc (length bytes)) (length (code-page-code page))))
(setf (code-page-alloc page) (+ alloc (length bytes)))))
pages bytes)
;; and return the offset for that code sequence
alloc))
This function is used by emit-all-code to emit the machine code for
a bunch of primitives, while tracking the start offset for each
primitive.
These are relatively tight. I certainly like how little data
shuffling there is; the NEXT sequence is a bit hairy, but the
indirect branch is likely its weakest (and least avoidable) point.
Control flow primops
A VM without control flow isn’t even a toy. First, unconditional
relative jumps. These can be encoded as [jmp] [offset], with the 32
bit offset relative to the end of offset. We just overwrite
*virtual-ip* with the new address.
We finally almost have enough for interesting demos. The only
important thing that’s still missing is calls from CL into the VM.
I’ll assume that the caller takes care of saving any important
register, and that the primop (rsi) and virtual IP (rdi) registers
are setup correctly. The stack will be filled on entry, by copying
values from the buffer rax points to, and written back on exit.
12345678910111213141516171819
(defun enter ()
(inst push sb-vm::rbp-tn)
(inst mov sb-vm::rbp-tn sb-vm::rsp-tn) ; setup a normal frame
(inst push *rax*) ; stash rax
(dotimes (i 8) ; copy the stack in
(inst mov (@ i) (make-ea :dword :base *rax* :disp (* 4 i))))
(next))
(defun leave ()
;; restore RAX
(inst mov *rax* (make-ea :qword :base sb-vm::rbp-tn :disp -8))
;; overwrite the output stack
(dotimes (i 8)
(inst mov (make-ea :dword :base *rax* :disp (* 4 i))
(@ i)))
;; and unwind the frame
(inst mov sb-vm::rsp-tn sb-vm::rbp-tn)
(inst pop sb-vm::rbp-tn)
(inst ret))
The CL-side interlocutor of enter follows, as a VOP:
We can now either write (basically) straightline code or infinite
loops. We need conditionals. Their implementation is much like
jmp, with a tiny twist. Let’s start with jump if (top of stack is)
non-zero and jump if zero.
1234567891011121314151617
(defun jcc (cc)
;; next word is the offset if the condition is met, otherwise,
;; fall through.
(inst movsx *rax* (make-ea :dword :base *virtual-ip*))
(inst lea *rax* (make-ea :dword :base *virtual-ip* :index *rax*
:disp 4))
(inst add *virtual-ip* 4)
(inst test (@ 0) (@ 0))
;; update *virtual-ip* only if zero/non-zero
(inst cmov cc *virtual-ip* *rax*)
(next))
(defun jnz ()
(jcc :nz))
(defun jz ()
(jcc :z))
Immediates
It’s hard to write programs without immediate values. Earlier control
flow primitives already encode immediate data in the virtual
instruction stream. We’ll do the same for lit, inc, and dec:
123456789101112
(defun lit ()
(decf *stack-pointer*) ; grow the stack
(inst mov (@ 0) (make-ea :dword :base *virtual-ip*)) ; load the next word
(next 4)) ; and skip to the next instruction
(defun inc ()
(inst add (@ 0) (make-ea :dword :base *virtual-ip*))
(next 4))
(defun dec ()
(inst sub (@ 0) (make-ea :dword :base *virtual-ip*))
(next 4))
My first loop
Finally, we have enough for a decent-looking (if useless) loop. First,
update the primop code page:
12345678
;; C-M-x to force re-evaluation, or defparameter
(defvar *primops* '(enter leave lit
swap dup drop
add sub inc dec
jmp jnz jz
call ret))
(defvar *primops-offsets* (assemble-primops))
12345678910
CL-USER> (vm '(1000000) (assemble '(lit 1 sub jnz -20 leave))
*code-page*)
Evaluation took:
0.009 seconds of real time
0.009464 seconds of total run time (0.009384 user, 0.000080 system)
100.00% CPU
14,944,792 processor cycles
0 bytes consed
#(0 0 0 0 0 0 0 1)
One million iterations of this stupid loop that only decrements a
counter took 15M cycles. 15 cycles/iteration really isn’t that
bad… especially considering that it executes an indirect jump after
loading 1, after subtracting, and after comparing with 0.
We can do better by fusing lit sub into dec:
12345678910
CL-USER> (vm '(1000000) (assemble '(dec 1 jnz -16 leave))
*code-page*)
Evaluation took:
0.007 seconds of real time
0.006905 seconds of total run time (0.006848 user, 0.000057 system)
100.00% CPU
11,111,128 processor cycles
0 bytes consed
#(0 0 0 0 0 0 0 0)
Fuse all the things!
Decrementing a counter and jumping if non zero is a common operation
(old x86 even implemented that in hardware, with loop). Let’s add
decrement and jump if non-zero (djn) to the VM:
CL-USER> (vm '(1000000) (assemble '(djn -8 leave))
*code-page*)
Evaluation took:
0.005 seconds of real time
0.005575 seconds of total run time (0.005542 user, 0.000033 system)
120.00% CPU
8,823,896 processor cycles
0 bytes consed
#(0 0 0 0 0 0 0 0)
That’s better… But I’m really not convinced by the conditional move.
The branch will usually be predictable, so it makes sense to expose
that to the hardware and duplicate the NEXT sequence.
12345678910
(defun djn2 ()
(sb-assem:assemble ()
(inst sub (@ 0) 1)
(inst jmp :z fallthrough)
(inst movsx *rax* (make-ea :dword :base *virtual-ip*))
(inst lea *virtual-ip* (make-ea :dword :base *virtual-ip* :index *rax*
:disp 8))
(next -4) ; might as well pre-increment *virtual-ip*
fallthrough ; ASSEMBLE parses for labels, like TAGBODY
(next 4)))
The resulting code isn’t too large, and the two indirect jumps are 16
bytes apart.
This alternative implementation does work better on our stupid loop.
12345678910
CL-USER> (vm '(1000000) (assemble '(djn2 -8 leave))
*code-page*)
Evaluation took:
0.004 seconds of real time
0.004034 seconds of total run time (0.003913 user, 0.000121 system)
100.00% CPU
6,183,488 processor cycles
0 bytes consed
#(0 0 0 0 0 0 0 0)
Let’s see how that compares to straight assembly code.
123456
(defun ubench ()
(sb-assem:assemble ()
head
(inst sub (@ 0) 1)
(inst jmp :nz head)
(next)))
12345678910
CL-USER> (vm '(1000000) (assemble '(ubench leave))
*code-page*)
Evaluation took:
0.000 seconds of real time
0.000629 seconds of total run time (0.000628 user, 0.000001 system)
100.00% CPU
1,001,904 processor cycles
0 bytes consed
#(0 0 0 0 0 0 0 0)
My slow macbook air gets 1 iteration/cycle on a loop that’s 100%
control overhead. With djn2, a good implementation of a reasonable
specialised operator, the loop is about 6x as slow as native code. A
worse implementation of djn is still only 8x as slow as pure native
code, and horribly unspecialised bytecode is 11-15x as slow as native
code.
Verdict
Specialising primops to a virtual stack pointer is feasible in
practice, when the stack is restricted to a small size. It also seems
to have a reasonable runtime overhead for threaded interpreters. I’m
not actually interested in straight stack languages; however, I
believe that a fixed stack VM makes a nice runtime IR, when coupled
with a mechanism for local variables. We’ll see if I find time to
translate a high level language into superoperators for such a VM.
Fused operators would reduce the importance of NEXT; in constrast,
simpler function calls (because there’s less shuffling of items to
stack them up in the right position) would remain as useful.
SBCL has definitely proven itself to be a good companion to explore
the generation of domain-specific machine code. I don’t know of any
other language implementation with that kind of support for
interactive programming and machine code generation (and inspection).
FWIW, I believe LuaJIT + dynasm will soon be comparable.
Steel Bank Common Lisp: because sometimes C abstracts away too much ;)