Back in 2014, AppNexus needed a faster way to convert machine integers to strings. It’s a stupid problem to have–just use a binary format–but it’s surprisingly common. Maybe a project can only grow large enough for serialisation speed to be an issue if it first disregards some trivial concerns. I can finally share our solution: after failing to nicely package our internal support code for years, we recently got the OK to open source the AppNexus Common Framework (ACF) under the Apache License 2.0, despite its incomplete state.
In the words of a friend and former colleague:
Two years of my life in one repository....
— John Wittrock (@johnwittrock) December 19, 2017
Congrats @pkhuong @arexus and all! https://t.co/jPFnYrc5V4
If you don’t want to read more about what’s in ACF and why I feel
it’s important to open source imperfect repositories,
jump to the section on fast itoa.
ACF contains the base data structure and runtime library code we use to build production services, in C that targets Linux/x86-64. Some of it is correctly packaged, most of it just has the raw files from our internal repository. Ironically, after settling on the project’s name, we decided not to publish the most “framework-y” bits of code: it’s unclear why anyone else would want to use it. The data structures are in C, and tend to be read-optimised, with perhaps some support for non-blocking single-writer/multi-reader concurrency. There’s also non-blocking algorithms to support the data structures, and basic HTTP server code that we find useful to run CPU-intensive or mixed CPU/network-intensive services.
Publishing this internal code took a long time because we were trying to open a project that didn’t exist yet, despite being composed of code that we use every day. AppNexus doesn’t sell code or binaries. Like many other companies, AppNexus sells services backed by in-house code. Our code base is full of informal libraries (I would be unable to make sense of the code base if it wasn’t organised that way), but enforcing a clean separation between pseudo-libraries can be a lot of extra work for questionable value.
These fuzzy demarcations are made worse by the way we imported some ideas directly from Operating Systems literature, in order to support efficient concurrent operations. That had a snowball effect: everything, even basic data structures, ends up indirectly depending on runtime system/framework code specialised for our use case. The usual initial offenders are the safe memory reclamation module, and the tracking memory allocator (with a bump pointer mode); both go deep in internals that probably don’t make sense outside AppNexus.
Back in 2015, we looked at our support code (i.e., code that doesn’t directly run the business) and decided we should share it. We were–and still are–sure that other people face similar challenges, and exchanging ideas, if not directly trading code, can only be good for us and for programming in general. We tried to untangle the “Common” (great name) support library from the rest of the code base, and to decouple it from the more opinionated parts of our code, while keeping integration around (we need it), but purely opt-in.
That was hard. Aiming for a separate shared object and a real Debian package made it even harder than it had to be. The strong separation between packaged ACF code and the rest of repo added a lot of friction, and the majority of the support code remained in-tree.
Maybe we made a mistake when we tried to librarify our internals. We want a library of reusable code; that doesn’t have to mean a literal shared object. I’m reminded of the two definitions of portable code: code sprinkled with platform conditionals, or code that can be made to run on a new machine with minimal effort. Most of the time, I’d rather have the latter. Especially when code mostly runs on a single platform, or is integrated in few programs, I try to reduce overhead for the common case, while making reuse possible and easy enough that others can benefit.
And that’s how we got the ACF effort out of the door: we accepted that the result would not be as polished as our favourite open source libraries, and that most of the code wouldn’t even be packaged or disentangled from internals. That’s far from an ideal state, but it’s closer to our goals than keeping the project private and on the backburner. We got it out by “feature” boxing the amount of work–paring it down to figuring out what would never be useful to others, and tracking down licenses and provenance–before pushing the partial result out to a public repository. Unsurprisingly, once that was done, we completed more tasks on ACF in a few days than we have in the past year.
Now that ACF is out, we still have to figure out the best way to help others co-opt our code, to synchronise the public repository with our internal repository, and, in my dreams, to accept patches for the public repo and have them also work for the internal one. In the end, what’s important is that the code is out there with a clear license, and that someone with similar problems can easily borrow our ideas, if not our code.
The source isn’t always pretty, and is definitely not as well packaged and easily re-usable as we’d like it to be, but it has proved itself in production (years of use on thousands of cores), and builds to our real needs. The code also tries to expose correct and efficient enough code in ways that make correct usage easy, and, ideally, misuse hard. Since we were addressing specific concrete challenges, we were able to tweak contracts and interfaces a bit, even for standard functionality like memory allocation.
The last two things are what I’m really looking for when exploring other people’s support code: how did usage and development experience drive interface design, and what kind of non-standard tradeoffs allowed them to find new low-hanging fruits?
If anyone else is in the same situation, please give yourself the permission to open source something that’s not yet fully packaged. As frustrating as that can be, it has to be better than keeping it closed. I’d rather see real, flawed but production-tested, code from which I can take inspiration than nothing at all.
How to print integers faster
¶ The
integer to string conversion file (an_itoa)
is one instance of code that relaxes the usual [u]itoa contract
because it was written for a specific problem (which also gave us
real data to optimise for). The relaxation stems from the fact that
callers should reserve up to 10 chars to convert 32 bit (unsigned)
integers, and 20 chars for 64 bit ones: we let the routines write
garbage (0/NUL bytes) after the converted string, as long as it’s
in bounds. This allowance, coupled with a smidge of thinking, let us
combine a few cute ideas to solve the depressingly common problem of
needing to print integers quickly.
Switching to an_itoa
might be a quick win for someone else, so I cleaned it up
and packaged it immediately after making the repository public.
We wrote an_itoa in July 2014. Back then, we had an application
with a moderate deployment (a couple racks on three continents) that
was approaching capacity. While more machines were in the pipeline, a
quick perf run showed it was spending a lot of time converting
strings to integers and back. We already had a fast-ish string to
integer function. Converting machine integers back to string however,
is a bit more work, and took up around 20% of total CPU time.
Of course, the real solution here is to not have this problem. We shouldn’t have been using a human-readable format like JSON in the first place. We had realised the format would be a problem a long time ago, and were actually in the middle of a transition to protobuf, after a first temporary fix (replacing a piece of theoretically reconfigurable JavaScript that was almost never reconfigured with hardcoded C that performed the same JSON manipulation). But, there we were, in the middle of this slow transition involving terabytes of valuable persistent data, and we needed another speed boost until protobuf was ready to go.
When you’re stuck with C code that was manually converted, line by line, from JavaScript, you don’t want to try and make high level changes to the code. The only reasonable quick win was to make the conversion from integer to string faster.
Human readable formats wasting CPU cycles to print integers is a
common problem, and we quickly found a few promising approaches and
libraries. Our baseline was the radix-10 code in
stringencoders.
This post about Lwan
suggested using radix-10, but generating strings backward instead of
reversing like the stringencoders library. Facebook apparently hit
a similar problem in 2013, which lead to
this solution
by Andrei Alexandrescu. The Facebook code combines two key
ideas: radix-100 encoding, and finding the length of the string with
galloping search to write the result backward, directly where it
should go.
Radix-100 made sense, although I wasn’t a fan of the 200-byte lookup
table. I was also dubious of the galloping search; it’s a lot of
branches, and not necessarily easy to predict. The kind of memmove
we need to fixup after conversion is small and easy to specialise on
x86, so we might not need to predict the number of digits at all.
I then looked at the microbenchmarks for Andrei’s code, and they made it look like the code was either tested on integers with a fixed number of digits (e.g., only 4-digit integers), or randomly picked with uniform probability over a large range.
If the number of digits is fixed, the branchiness of galloping search
isn’t an issue. When sampling uniformly… it’s also not an issue
because most integers are large! If I pick an integer at random in
[0, 1e6), 90% of the integers have 6 digits, 99% 5 or 6, etc.
Sometimes, uniform selection is representative of the real workload (e.g., random uids or sequential object ids). Often, not so much. In general, small numbers are more common; for example, small counts can be expected to roughly follow a Poisson distribution.
I was also worried about data cache footprint with the larger lookup
table for radix-100 encoding, but then realised we were converting
integers in tight loops, so the lookup table should usually be hot.
That also meant we could afford a lot of instruction bytes; a multi-KB
atoi function wouldn’t be acceptable, but a couple hundred bytes was
fine.
Given these known solutions, John and I started doodling for a bit. Clearly, the radix-100 encoding was a good idea. We now had to know if we could do better.
Our first attempt was to find the number of decimal digits more quickly than with the galloping search. It turns out that approximating \(\log\sb{10}\) is hard, and we gave up ;)
We then realised we didn’t need to know the number of decimal digits. If we generated the string in registers, we could find the length after the fact, slide bytes with bitwise shifts, and directly write to memory.
I was still worried about the lookup table: the random accesses in the
200 byte table for radix-100 encoding could hurt when converting short
arrays of small integers. I was more comfortable with some form of
arithmetic that would trade best-case speed for consistent, if slightly
sub-optimal, performance. As it turns out, it’s easy to convert values
between 0 and 100 to
unpacked BCD
with a reciprocal multiplication by \( 1/10 \) and some in-register
bit twiddling. Once we have a string of BCD bytes buffered in a
general purpose register, we can vertically add '0' to every byte in
the register to convert to ASCII characters. We can even do the whole
conversion on a pair of such values at once, with SIMD within a
register.
The radix-100 approach is nice because it chops up the input two digits at a time; the makespan for a given integer is roughly half as long, since modern CPUs have plenty of execution units for the body.
The dependency graph for radix-10 encoding of 12345678 looks like
the following, with 7 serial steps.
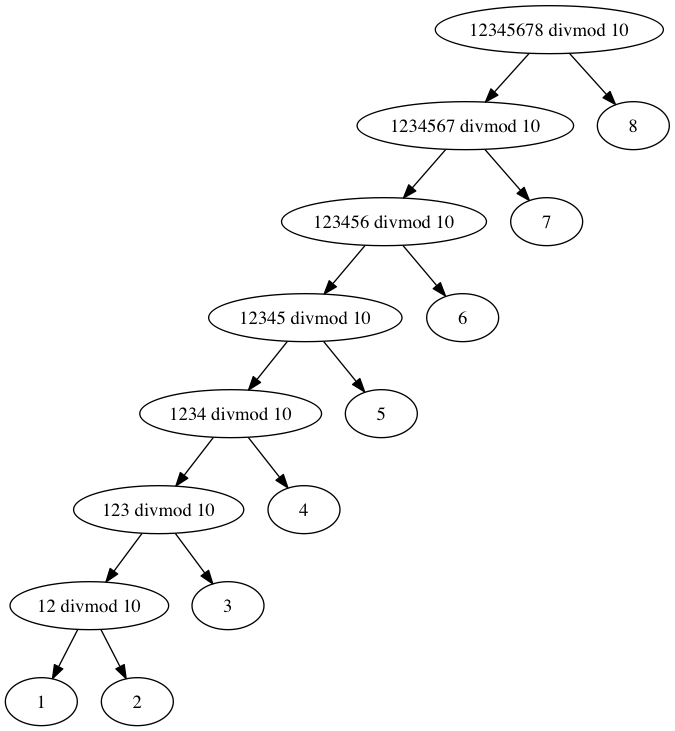
Going for radix-100 halves the number of steps, to 4. The steps are
still serial, except for the conversion of integers in [0, 100) to
strings.
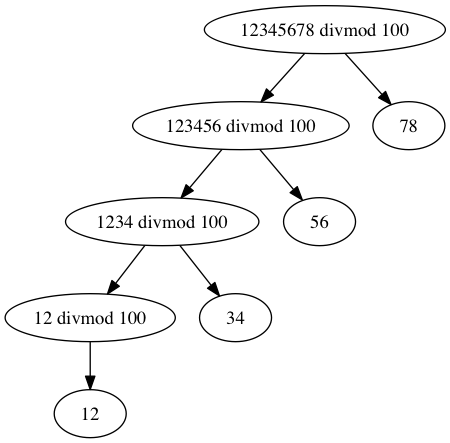
Could we expose even more ILP than the radix-100 loop?
The trick is to divide and conquer: divide by 10000 (1e4) before
splitting each group of four digits with a radix-100 conversion.
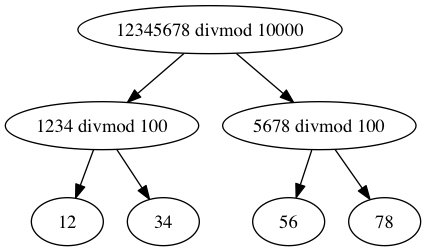
Recursive encoding gives us fewer steps, and 2 of the 3 steps can execute in parallel. However, that might not always be worth the trouble for small integers, and we know that small numbers are common. Even if we have a good divide-and-conquer approach for larger integers, we must also implement a fast path for small integers.
The fast path for small integers (or the most significant limb of
larger integers) converts a 2- or 4- digit integer to unpacked BCD,
bitscans for the number of leading zeros, converts the BCD to ASCII by
adding '0' (0x30) to each byte, and shifts out any leading zero;
we assume that trailing noise is acceptable, and it’s all NUL bytes
anyway.
For 32-bit integers
an_itoa
(really an_uitoa) looks like:
if number < 100:
execute specialised 2-digit function
if number < 10000:
execute specialised 4-digit function
partition number with first 4 digits, next 4 digits, and remainder.
convert first 2 groups of 4 digits to string.
If the number is < 1e8: # remainder is 0!
shift out leading zeros, print string.
else:
print remainder # at most 100, since 2^32 < 1e10
print strings for the first 2 groups of 4 digits.
The 64 bit version,
an_ltoa
(really an_ultoa) is more of the same, with differences when the
input number exceeds 1e8.
Is it actually faster?
I’ve already concluded that cache footprint was mostly not an issue, but we should still made sure we didn’t get anything too big.
an_itoa: 400 bytes.an_ltoa: 880 bytesfb_itoa: 426 bytes + 200 byte LUTfb_constant_itoa(without the galloping search): 172 bytes + 200 byte LUTlwan_itoa(radix-10, backward generation): 60 bytes.modp_uitoa10: 91 bytes.
The galloping search in Facebook’s converter takes a lot of space
(there’s a ton of conditional branches, and large numbers must be
encoded somewhere). Even if we disregard the lookup table, an_itoa
is smaller than fb_itoa, and an_ltoa (which adds code for > 32
bit integers) is only 254 bytes larger than fb_itoa (+ LUT). Now,
Facebook’s galloping search attempts to make small integers go faster
by checking for them first; if we convert small numbers, we don’t
expect to use all ~250 bytes in the galloping search. However,
an_itoa and an_ltoa are similar: the code is setup such that
larger numbers jump forward over specialised subroutines for small
integers. Small integers thus fall through to only execute code at
the beginning of the functions. 400 or 800 bytes are sizable
footprints compared to the 60 or 90 bytes of the radix-10 functions,
but acceptable when called in tight loops.
Now that we feel like the code and lookup table sizes are reasonable (something that microbenchmarks rarely highlight), we can look at speed.
I first ran the conversion with random integers in each digit count
class from 1 digit (i.e., numbers in [0, 10)) to 19 (numbers in
[1e8, 1e9)). The instruction cache was hot, but the routines were
not warmed on that size class of numbers (more realistic that way).
The results are cycle counts (with the minimum overhead for a no-op conversion subtracted from the raw count), on an unloaded 2.4 GHz Xeon E5-2630L, a machine that’s similar to our older production hardware.
We have data for:
an_itoa, our 32 bit conversion routine;an_ltoa, our 64 bit conversion routine;fb_constant_itoa, Facebook’s code, with the galloping search stubbed out;fb_itoa, Facebook’s radix-100 code;itoa, GNU libc conversion (via sprintf);lw_itoa, Lwan’s backward radix-10 converter;modp, stringencoder’s radix-10 /strreverseconverter.
I included fb_constant_itoa to serve as a lower bound on the
radix-100 approach: the conversion loop stops as soon as it hits 0
(same as fb_itoa), but the data is written at a fixed offset, like
lw_itoa does. In both fb_constant_itoa’s and lw_itoa’s cases,
we’d need another copy to slide the part of the output buffer that was
populated with characters over the unused padding (that’s why
fb_itoa has a galloping search).
When I chose these functions back in 2014, they were all I could find that was reasonable. Since then, I’ve seen one other divide and conquer implementation, although it uses a lookup table instead of arithmetic to convert radix-100 limbs to characters, and an SSE2 implementation that only pays off for larger integers (32 bits or more).
Some functions only go up to UINT32_MAX, in which case we have no
data after 9 digits. The raw data is here; I used
this R script to generate the plot.
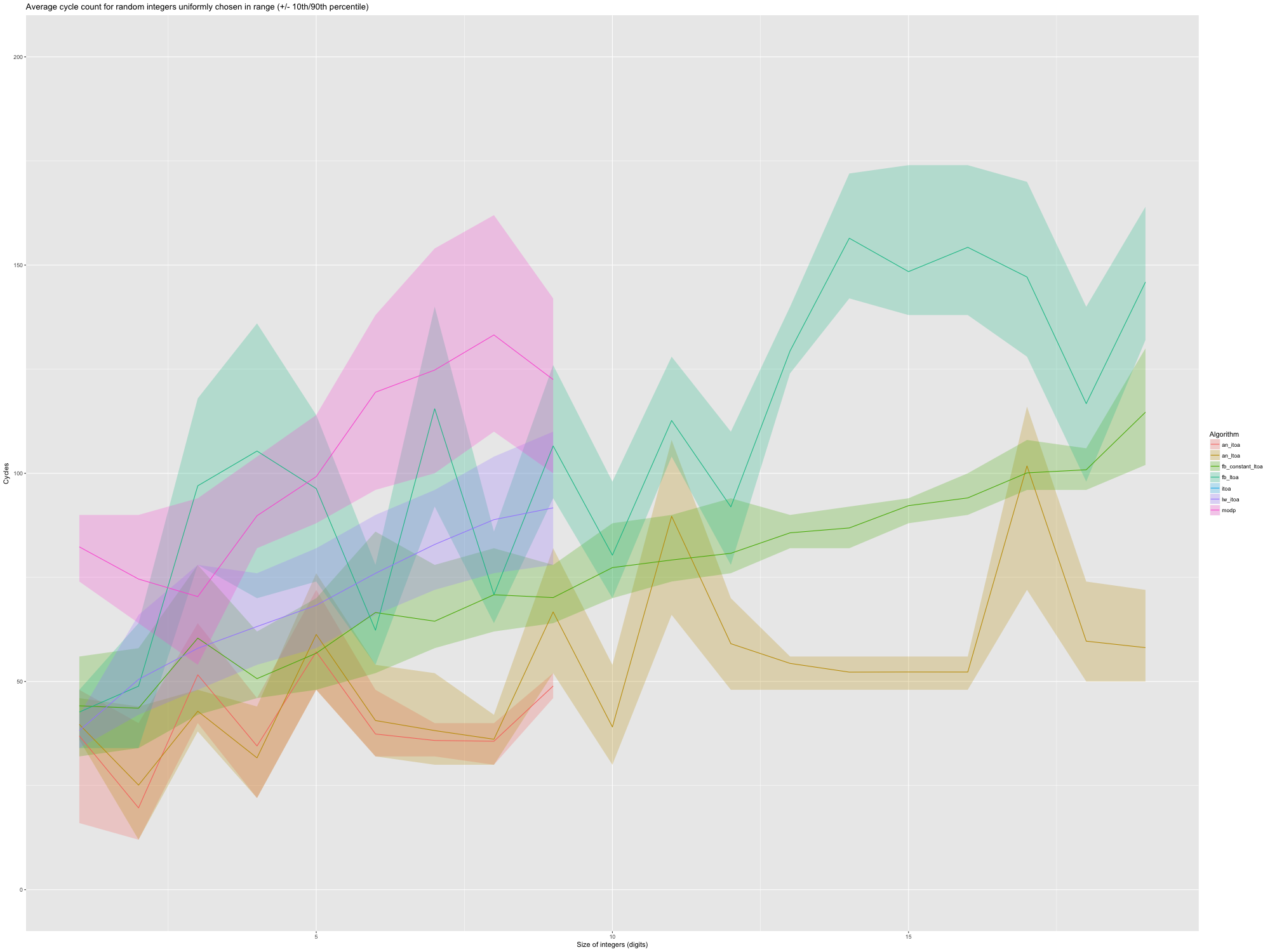
The solid line is the average time per conversion (in cycles), over 10K data points, while the shaded region covers the 10th percentile to the 90th percentile.
(GNU) libc’s conversion is just wayy out there. The straightforward
modp (stringencoders) code overlaps with Facebook’s itoa; it’s
slightly slower, but so much smaller.
We then have two incomplete string encoders: neither
fb_constant_itoa nor lw_itoa generates their output where it should
go. They fill a buffer from the end, and something else (not
benchmarked) is responsible for copying the valid bytes where they
belong. If an incomplete implementation suffices, Lwan’s radix-10
approach is already competitive with, arguably faster than, the
Facebook code. The same backward loop, but in radix-100, is
definitely faster than Facebook’s full galloping search/radix-100
converter.
Finally, we have an_itoa and an_ltoa, that are neck and neck with
one another, faster than both modp and fb_itoa on small and large
integers, and even comparable with or faster than the incomplete
converters. Their runtime is also more reliable (less variance) than
modp’s and fb_itoa’s: modp pays for the second variable length
loop in strreverse, and fb_itoa for the galloping search. There
are more code paths in an_itoa and an_ltoa, but no loop, so the
number of (unpredictable) conditional branches is lower.
What have we learned from this experiment?
- It’s easy to improve on (g)libc’s
sprintf. That makes sense, since that code is so generic. However, in practice, we only convert to decimal, some hex, even less octal, and the rest is noise. Maybe we can afford to special case these bases. - The double traverse in
modp_uitoa10hurts. It does make sense to avoid that by generating backward, ideally in the right spot from the start. - Radix-100 encoding is a win over radix-10 (
fb_constant_itoais faster thanlwan_itoa). - Using registers as buffers while generating digits is a win
(
an_itoaandan_ltoaare faster for small values). - Divide and conquer is also a win (
an_ltoais flatter for large integers).
With results that made sense for an easily understood microbenchmark, I decided to try a bunch of distributions. Again, the code was hot, the predictors lukewarm, and we gathered 10K cycle counts per distribution/function. The raw data is here, and I used this R script to generate the plot.
The independent variables are all categorical here, so I use one facet per distribution, and, in each facet, a boxplot per conversion function, as well as a jittered scatter plot to show the distribution of cycle counts.
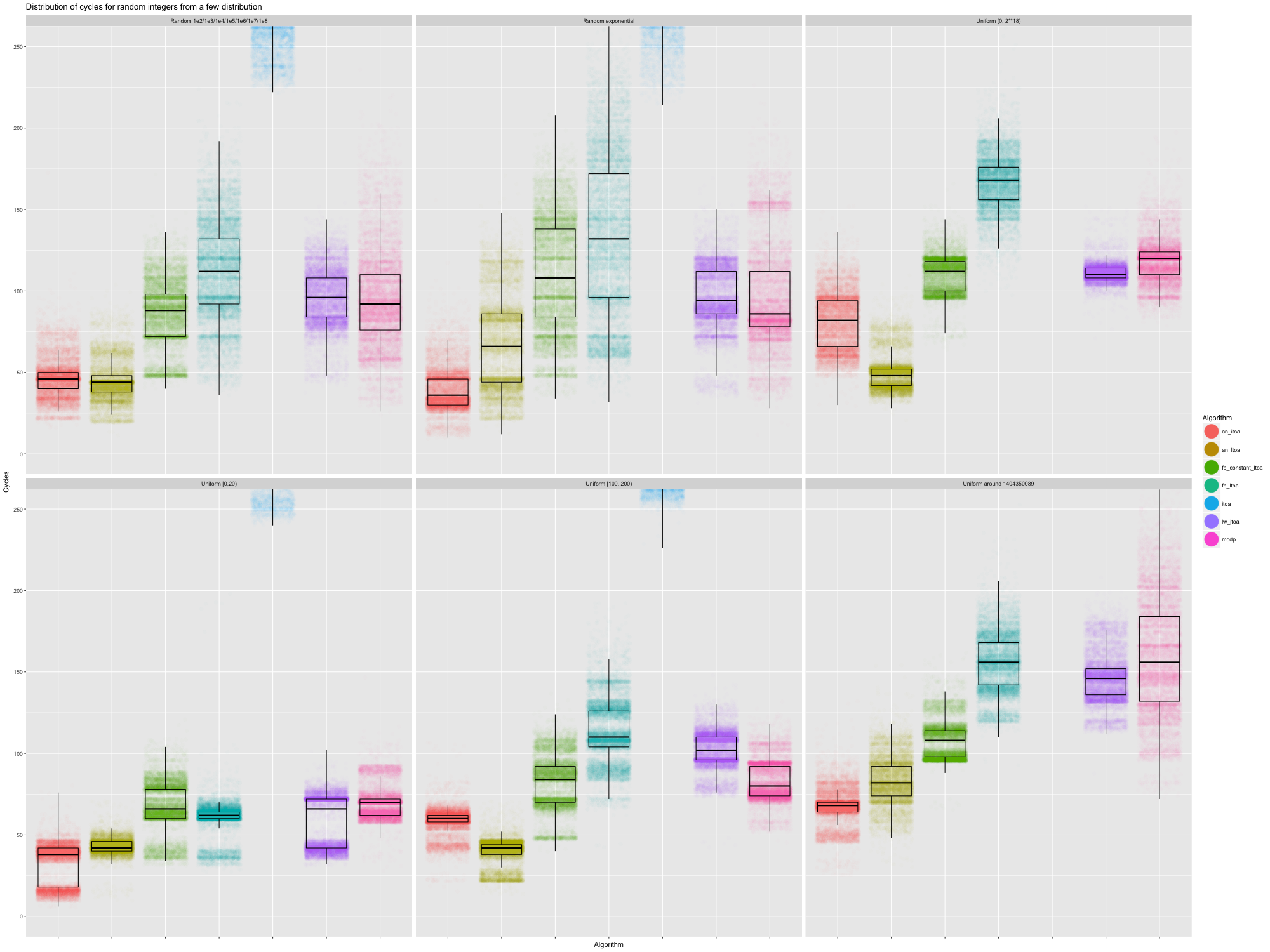
Clearly, we can disregard glibc’s sprintf (itoa).
The first facet generated integers by choosing uniformly between
\(100, 1000, 10\sp{4}, \ldots, 10\sp{8}\). That’s a semi-realistic
variation on the earlier dataset, which generated a bunch of numbers in
each size class, and serves as an easily understood worst-case for
branch prediction. Both an_itoa and an_ltoa are faster than the
other implementations, and branchier implementations (fb_itoa and
modp) show their variance. Facebook’s fb_itoa isn’t even faster
than modp’s radix-10/strreverse encoder. The galloping search
really hurts: fb_constant_itoa, without that component, is slightly
faster than the radix-10 lw_itoa.
The second facet is an even harder case for branch predictors: random
values skewed with an exponential (pow(2, 64.0 * random() / RAND_MAX)),
to simulate real-world counts. Both an_itoa and
an_ltoa are faster than the other implementations, although
an_ltoa less so: an_itoa only handles 32 bit integers, so it deals
with less entropy. Between the 32-bit implementations, an_itoa is
markedly faster and more consistent than lw_itoa (which is
incomplete) and modp. Full 64-bit converters generally exhibit more
variance in runtime (their input is more randomised), but an_ltoa is
still visibly faster than fb_itoa, and even than the incomplete
fb_constant_itoa. We also notice that fb_itoa’s runtimes are more
spread out than fb_constant_itoa: the galloping search adds overhead
in time, but also a lot of variance. That makes me think that the
Facebook code is more sensitive than others to difference in data
distribution between microbenchmarks and production.
The third facet should be representative of printing internal
sequential object ids: uniform integers in [0, 256K). As expected,
every approach is tighter than with the skewed “counts” distribution
(most integers are large). The an_itoa/an_ltoa options are faster
than the rest, and it’s far from clear that fb_itoa is preferable to
even modp. The range was also chosen because it’s somewhat of a
worst case for an_itoa: the code does extra work for values between
\(10\sp{4}\) and \(10\sp{8}\) to have more to do before the
conditional branch for x < 1e8. That never pays off in the range
tested here. However, even with this weakness, an_itoa still seems
preferable to fb_itoa, and even to the simpler modp_uitoa10.
The fourth facet (first of the second row) shows what happens when we
choose random integers in [0, 20). That test case is interesting
because it’s small, thus semi-representative of some of our counts,
and because it needs 1 or 2 digits with equal probability. Everything
does pretty well, and runtime distributions are overall tight; branch
predictors can do a decent job when there are only two options. I’m
not sure why there’s such a difference between an_itoa and
an_ltoa’s distribution. Although the code for any value less than
100 is identical at the C level, there are small difference in code
generation… but I can’t pinpoint where the difference might come from.
The fifth facet, for random integers in [100, 200) is similar, with
a bit more variance.
The sixth facet generates unix timestamps around a date in 2014 with
uniform selection plus or minus one million second. It’s meant to be
representative of printing timestamps. Again, an_itoa and an_ltoa
are faster than the rest, with an_itoa being slightly faster and
more consistent. Radix-100 (fb_constant_itoa) is faster and more
consistent than radix-10 (lw_itoa), but it’s not clear if fb_itoa
is preferable to modp. The variance for modp is larger than for
the other implementations, even fb_itoa: that’s the cost of a
radix-10 loop and of the additional strreverse.
This set of results shows that conditional branches are an issue when
converting integers to strings, and that the impact of branches
strongly depends on the distribution. The Facebook approach, with a
galloping search for the number of digits, seems particularly
sensitive to the distribution. Running something like fb_itoa
because it does well in microbenchmark is thus only a good idea if we
know that the microbenchmark is representative of production.
Bigger numbers take more time to convert, but the divide and conquer
approach of an_itoa and an_ltoa is consistently faster at the high
end, while their unrolled SIMD-within-a-register fast path does well for
small numbers.
So, if you ever find yourself bottlenecked on s[n]printf
The correct solution to the “integer printing is too slow” problem is simple: don’t do that. After all, remember the first rule of high performance string processing: “DON’T.” When there’s no special requirement, I find Protobuf does very well as a better JSON.
However, once you find yourself in this bad spot, it’s trivial to do better than generic libc conversion code. This makes it a dangerously fun problem in a way… especially given that the data distribution can matter so much. No benchmark is perfect, but various implementations are affected differently by flaws in microbenchmarks. It’s thus essential not to overfit on the benchmark data, probably even more important than improving performance by another factor of 10% or 20% (doing 4-5x better than libc code is already a given). That’s why I prefer integer conversion code with more consistent cycle counts: there’s less room for differences due to the distribution of data.
Finally, if, like 2014-AppNexus, you find yourself converting a lot of
integers to strings in tight loops (on x86-64 machines),
try an_itoa or an_ltoa!
The whole repository is Apache 2.0,
and it should be easy to copy and paste all the dependencies to pare
it down to two files. If you do snatch our code, note that the
functions use their destination array (up to 10 bytes for an_itoa,
and 20 for an_ltoa) as scratch space, even for small integers.
Thank you for reviewing drafts, John, Ruchir, Shreyas, and Andrew.