Searching in a short, sorted vector is a fairly common task. Lots of time, data sets are just small enough that it’s quicker (and simpler) to store them in a sorted vector than to use an alternative with asymptotically faster insertions. Even when we do use more complex data structures, it often makes sense to specialise the leaves and pack more data in a single node.
How should we implement such a search? There are two basic options: linear and binary search. After running a bunch of tests, I claim that a decent binary search offers good and robust performance, and is nearly always the right choice. An interpolation search could be appropriate, but it’s a tad too complicated for short vectors, and can fail hard if the input is arranged just wrong.
When the data is expected to be in cache, binary search is pretty much always preferable. When it isn’t, binary search is faster for short (at most one or two cache line) and long vectors, but a good linear search can be the best option for data that fits in a couple cache lines.
I’ll focus on one specific case that is of interest to me: searching a
short or medium-length sorted vector of known size. I’m interested in
micro-optimisations, so I’ll only work on vectors of 32-bit unsigned
values. I’m also assuming we’re looking for a
lower bound, because
that’s what I need.
Some
other people
have looked into this, but I consider more cases and use
size-specialised code. I also try to represent the whole distribution
of runtimes, which helps us take long tails into account: I’m
usually willing to take a small hit in average performance for an
improvement in consistency.
Branch mispredictions and entropy
X86 processors have been pipelined for quite a while now, and (mispredicted) conditional branches are well known for wrecking the performance of programs: when a branch is predicted wrong, all the work that’s been speculatively done so far must be thrown out. In effect, the processor’s massive execution resources have then been completely wasted from the moment the branch is decoded until it is retired (out of order execution improves on things a bit, but the end result is the same).
Of course, things aren’t as bad as they once were with the old
P4.
That one exhibited an awesome combination of a preternaturally long
pipeline, slow conditional moves, slow shifts, and extra latency on
any instruction that used the condition flags. I don’t think I can
convey how frustrating that microarchitecture could be… Mispredicted
branches killed IPC, but conditional moves were only slightly better,
and more portable bit-twiddling tricks (generating masks from the sign
bit with sar, or from the carry flag via sbb) just as slow. I
believe Linus Torvalds once posted quite the rant on that topic on
RWT (:
Still, I think we can tell the period has left its mark on many programmers who will go to great lengths to avoid anything that looks like a branch. One common symptom is the notion that it’s normal for a linear search to execute faster than a binary search, even on vectors of 32 or 64 values. The reasoning is that the branches in a linear search are trivially predicted: the comparison always fails, except for the very last once. In contrast, the comparisons in a binary search are hard to predict: there are only \(\lg n\) of them, so each one extracts one full bit of information from the vector. In other words, linear search is expected to run better because each conditional extracts less information: the predictors have less entropy to deal with, and are right more often… “It’s better to execute many nearly useless branches.” (!?)
Not all conditionals are created equal
Sometimes, it really is faster to perform redundant work to avoid mispredicted branches. However, that’s definitely not the case for linear versus binary search. Linear search pretty much has to be implemented with conditional branches: we really want to abort early once we’ve found what we’re looking for. It’s not so clear-cut with binary search. I think it’s a standard exercise to ask why it doesn’t help that much to leave binary search early when we have an exact match. So, when the size is known ahead of time, the only remaining conditional is when we update the upper or the lower bound; that’s actually a conditional move. Fixed-length binary searches are naturally executed without any branch! It doesn’t get more prediction-friendly than that.
In short, we actually expect linear search to be faster than binary search only when conditional branches allow the former to leave the search loop early. Linear search can hope to overtake binary search because of its conditional branches!
Microbenchmarking for mispredictions
I tested this hypothesis on my 2.8 GHz X5660, in GCC. First the linear (lower bound) search:
1 2 3 4 5 6 7 8 9 10 | |
Size-specialised versions were generated by calling it with a constant
size argument. GCC unrolled the loop for size 16 and lower, which
seems more than reasonable to me. For larger sizes, the loop was not
unrolled at all. Again, that seems reasonable: current X86 have
special logic to accelerate such tiny (compare, conditional jump,
decrement) loop bodies.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
The linear search walks the data backwards, from high to low addresses, which is unusual. I also tested a slightly more complicated version that searches the data forward:
1 2 3 4 5 6 7 8 9 10 11 | |
The same size-specialisation trick was used for the binary search:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
I assume that the size is a power of two, so I only have to track the lower bracket of the search: the upper one is always at a known offset. The return value checks for a key that’s smaller than all the elements in the vector, rather than assuming the presence of a sentinel. That case doesn’t happen in the tests, and the conditional branch is always predicted right. I tried taking it out, and the difference was pretty much noise, on the order of one cycle.
Note that other sizes could be handled by special-casing the first
iteration and setting the midpoint to size - (1ul<<(lb(size)-1)).
If the midpoint becomes the lower bound, the rest of the search is on
a power-of-two–sized range; otherwise, the sequel is performed on a
wider than necessary range, but still correct. In both cases, the
number of iterations is the same as for a regular binary search.
There could be a slight loss of performance due to worse locality, but
the access patterns aren’t that different.
All sizes (up to 64, so six iterations) were fully unrolled. This is
expected, as the body is a simple cmp/lea/cmov.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Finally, I also tested a vectorised linear search, using SSE instructions. The implementations exploits vectorised comparisons to only perform at most one test per cache line (16 values). In fact for vectors of length 16 or less, there is no (mispredicted) branch at all. The implementation is actually broken, as it performs signed rather than unsigned comparisons, but that’s not an issue in the tests performed here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | |
The preliminary test is always correctly predicted, and only ends up
prefetching data that’ll be used a couple instructions later. A
similar trick as TEST2 is used to generate a bitmask from 16
comparisons. Finally, even when there are loops, they’re fully
unrolled. The disassembly below shows how the conditional branch
around return is compiled away in the last iteration. For all sizes
(up to 64), the loops were fully unrolled.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
Graphics time!
The first scenario was a search for random keys on an in-cache vector.
As for all other tests, 10 000 searches were performed, and the
overhead of the benchmarking loop was estimated with the minimal
iteration time when calling an empty function (44 cycles), and
subtracted from the measured values. Finally, extreme outliers
(values larger than the 99th percentile for each scenario, size and
algorithm) were removed. There’s a bit of overhead (rdtscp isn’t
exactly lightweight), so the shorter searches don’t reveal much,
except how complex current CPUs can be. I also tried measuring a
couple searches at a time, but that lost interesting information, and
let out of order execution mess the results up.
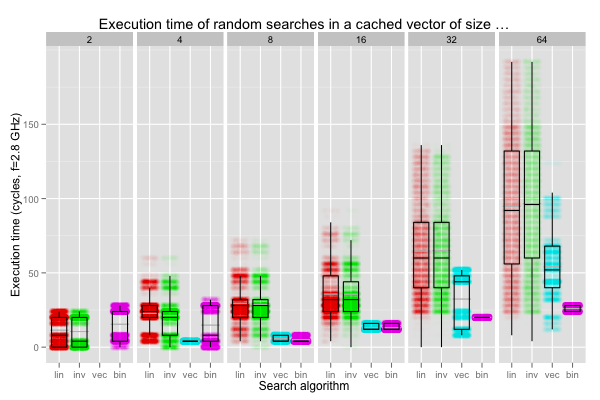
The graphics overlay a jittered scatter plot and a box plot. The density of points reveals how often each execution time (in clock cycle) was observed. The box plots give us the median and the first and third quartiles; the median is a more robust single-number summary than the mean on strange distributions. Still, I also included the arithmetic mean (without outliers) as a thin grey line. The search algorithms are, from left to right, forward linear search (“lin”), backward linear search (“inv”), vectorised forward linear search (“vec”), and binary search (“bin”). The size of the vector is reported at the top.
In general, interesting transitions will happen around length 16
(especially for forward and backward linear searches), and 32 for
binary search. Scalar linear searches longer than 16 elements aren’t
unrolled, the vectorised search works in chunks of up to 16 elements,
and 16 unsigneds fit exactly in one cache line. At length 32, binary
search may access one or two cache lines, depending on the data, and
vectorised search starts executing conditional branches.
The box plots are pretty clear. Except for vectors of length two or four (for which the benchmarking infrastructure probably dominates everything), binary search is always faster than linear search: the single mispredicted branch in the latter hurts. The vectorised search is always a bit quicker than the scalar versions and performs nearly identically to the binary search up to size 16. After that, it has to execute a few unpredictable branches. The distribution of runtimes for the vectorised search exhibits very distinct peaks, so the quartiles might not be as robust as they usually are.
The scatter plots are also interesting. First, they raise an interesting question as to what exactly is going on with the bimodal distribution on vectors of length two or four. I have no clue. Current CPUs are awfully complex stateful systems with strange interactions; I would guess a combination of back-to-back call and return, and the benchmarking code interfering with itself.
Over all vector sizes, the distribution of latencies for linear searches is distinctly multimodal: searches that end quickly execute much faster. The effect of batching by the cache line in the vectorised search is also visible. Unpredictable branches are only executed for length 32 or 64; the median times (and spread, obviously) then increase quite a lot. There’s also some variation between the forward and backward linear search; I frankly don’t know why the access pattern has that impact, or if it might not just be noise.
What happens if more regular queries help eliminate branch mispredictions? Obviously, binary search will not be affected, but we can expect the linear searches to execute more quickly.
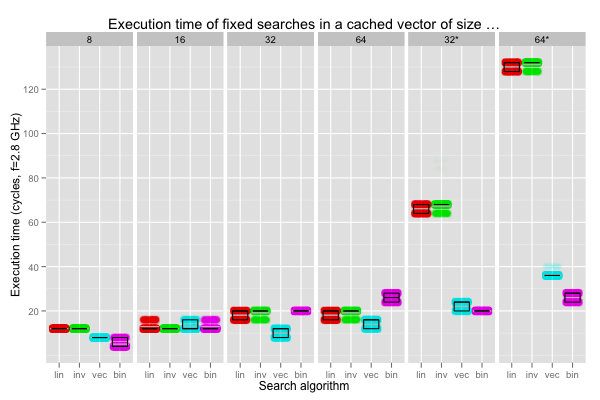
The leftmost four plots above show what happens when the linear searches always find the key after eight iterations (one for the vectorised search). The remaining two (“32*” and “64*”) instead set the key as the very last position that is searched.
In all cases, binary search remains the same. When the key is found quickly (first four plots), scalar linear searches are approximately on par with binary search, and the vectorised search faster. On the other hand, when the whole vector must be traversed (two rightmost plots), the linear searches take more than thrice as much time as the binary search! Even the vectorised search is at best comparable to the binary search. Comparing the top of the distribution in the first plot to this one shows that mispredicted branches can slow linear searches by up to 50ish cycles. However, it is still quicker overall to take the hit and break out of the search early: compare the medians. Conditional branches speed linear search up.
The effect isn’t as marked on the vectorised search, but it’s still slower than a binary search on the “32*” and “64*” plots. The branches are always predicted correctly, and we end up with a good approximation of a fully vectorised search. Rather than eliminating all the branches from the vectorised linear search (by always processing the whole vector), it’s simpler and faster to go for a binary search.
Mispredictions slow linear searches down, and traversing the data completely even more. The next plot summarises the timings for searches that succeed after the first or second iterations of (scalar) linear search. That’s almost the best environment I can think of for linear search, short of always searching for one value that’s found in the very first iterations.
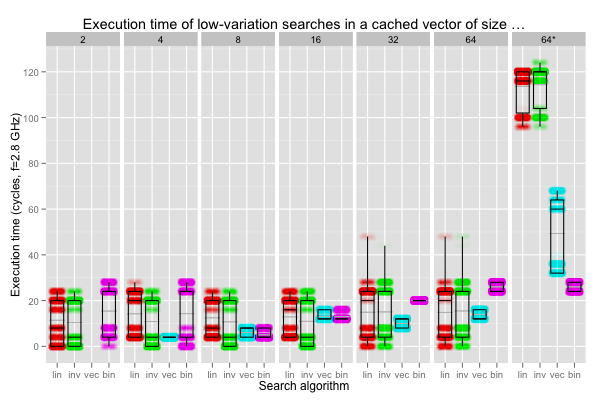
Even when they always succeed after at most two iterations, the linear searches are only slightly faster than a binary search, with a few very slow runs. The vectorised search is shown in its best light: it always succeeds on the first iteration and is, overall, comparable with the linear searches (with a tighter spread). Much like the binary search, vectorising minimises branches, but does so at the cost of additional work.
The “64*” plot exercises the vectorised search better: the element is found on the third or last iteration (48th or 49th for the linear searches). The binary search isn’t affected at all, and the linear searches become appreciably (by a factor of two or four) slower. Even with very regular queries, linear searches are, at best, slightly faster than binary search, and otherwise significantly slower.
When the data is expected to be cached, I believe it’s fair to say that binary search should always be used instead of linear searches, even unrolled vectorised (fully or not) versions. In the worst case, scalar linear searches can be more than 50 or 100 cycles slower than a decent binary search. In the best case, a partially vectorised linear search can save about 10 cycles. That sounds like a horrible bargain.
Let’s throw in some cache misses
When the data is cached, linear search only wins if we keep hammering the same query, and it’s found in the first iterations. What if the data isn’t cached? I ran another set of tests, this time hopping around 1 GB’s worth of short vectors. The vectors were aligned to their size, so the vectorised search worked naturally, and we can also easily think about cache lines. The vectors were chosen by picking vectors in different 4 KB pages, at every potential offsets from the start of the page, and shuffling them randomly to foil prefetching. This is pretty much a worst-case scenario: there’s both a TLB and an L3 miss (but the latency of a TLB miss varies a lot depending on which parts of the page table are still cached). I could also have tried to use huge pages (2MB) to eliminate TLB misses. I don’t think that’s realistic: huge pages aren’t widely used, and TLBs misses tend to be an issue even with working sets that are still big enough for L2. We can expect two things here: the timings will be orders of magnitude slower, and linear searches will eke speed-ups out by skipping some accesses, thanks to their conditional branches.
The first set of plots corresponds to random searches in out-of-cache vectors. Searches in even the shortest vectors are slow enough to be somewhat meaningful. We can observe that the latency of two accesses to the same cache line varies a lot, from 200 to 700 cycles. The distributions are strongly multimodal, and it’s not clear to me that comparing the quartiles is always useful: they sometimes fall in nearly-empty zones between two peaks, so I would expect tiny changes to affect them a lot. The plots for length up to eight are all very similar, so I’ll just drop sizes two and four in the sequel.
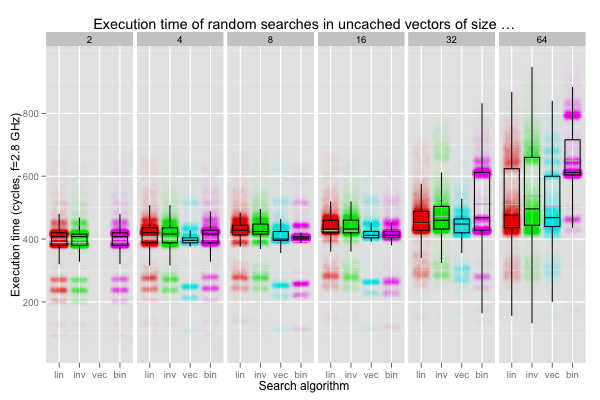
The forward linear searches (scalar and vectorised) are, over all, a bit faster than the backward one. That’s a bit counter-intuitive: vectors of size up to 16 fit in one cache line. That the latency from cache misses is always the same as soon as we touch a cache line is a useful lie: it’s usually good enough of an approximation. In the real world, chips don’t load whole cache lines atomically. Current sockets have hundreds of pins, but they can’t all be dedicated to communicating with DIMMs. On the X5660 where the tests were executed, single-core bandwidth is 8 GB/s. That’s exactly the bandwidth from one of its DDR3-1066 modules. DDR3 sends data in chunks of 64 bits, so that’s how one cache line is loaded: 64 bits at a time. The CPU’s memory controller first loads the chunk corresponding to the instruction that triggered a cache miss, and then the rest of the cache line. The controller simply seems to have been tuned for programs that load data from low to high addresses.
The binary search seems a tiny bit quicker than the other searches on
sizes up to 32, and fares badly on 64-element vectors. 16 unsigneds is
exactly one cache line, so it’s not surprising that 16 or fewer
(correctly aligned) elements can be binary searched quickly. The
size-32 case benefits from an implicit data dependency in binary
search. When the key falls in the latter half of the vector, only
that half will be read from: the initial midpoint is the first element
of that latter half. 32 unsigneds fit exactly in two cache lines, and
binary search thus behaves very similarly to linear searches: it reads
from only one cache line half the time, and otherwise from two. I
can’t explain the solid peak of occurrences around 600 cycles though.
Finally, the data dependency doesn’t help so much on vectors of length
64 (half of four cache lines is still two), and binary search is then
significantly slower.
Some of the variation in execution times must still be caused by branch mispredictions. The following plots show what happens if the key is always found after eight iterations of the scalar linear searches (one iteration of the vectorised search). The binary search is also slightly advantaged on sizes 16 and up, as the key is found in the latter half of the vector. The rightmost two plots fix the key so that it is found at the very last iteration of the searches, and disadvantages binary search by searching for the minimum value in the data.
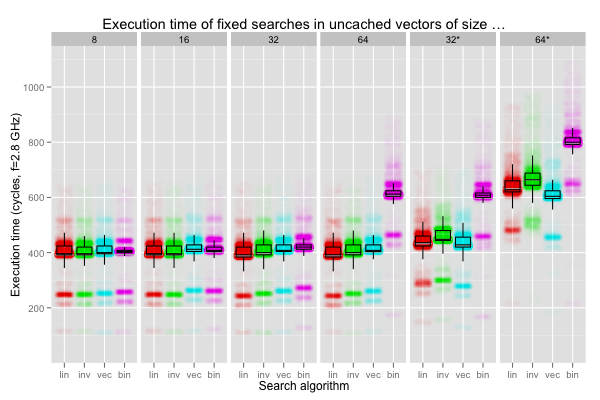
When the key is found early, the forward linear search seems a tiny bit faster than the rest, even the vectorised search (which trades more memory accesses for fewer branches). Interestingly, when the key is always found at the end, the linear searches aren’t affected that much; speculative execution seems to be doing its job at hiding latencies.
The last plots correspond to the situation when the key is found after one or two iterations (equiprobably) for the linear searches (one for the vectorised version, and in the last cache line for binary search). The “64*” column shows the latencies for a worse scenario: the key is found after 48 or 49 iterations of the linear searches (three or four for the vectorised search), and in the first quarter of data for binary search.
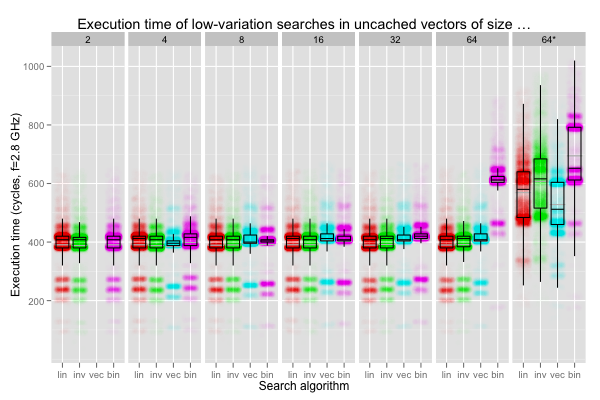
On the good cases, all searches seem to be doing similarly, except for vectors of length 64 (on which the binary search really suffers). In fact, comparing the “64” and “64*” plots reveals that binary search is affected by variations in the query just as much as linear searches: bad memory access patterns can hurt a lot more than mispredicted branches.
In the end it looks like all searches behave pretty much the same when searching uncached vectors spanning at most two cache lines. After that, linear searches have better access patterns (and after that, asymptotics catch up).
Wrapping up
When performance matters, linear search shouldn’t be preferred to binary search to minimise branch mispredictions. Linear search should only be used when it’s expected to bail out quickly. The situations in which that property is most useful involve uncached, medium-size vectors. In general, I’d just stick to binary search: it’s easy to get good and consistent performance from a simple, portable implementation.
In some cases, it might be worth the trouble to go for a heroically optimised linear search, but maintenance may be a bitch. If I expected to be working with larger, potentially uncached, datasets, I’d instead try to exploit caches more smartly… But that’s a topic for another post!
A friend of mine pointed out one case when a fully vectorised linear search, without early exit, may be the only (high-performance) option: cryptographic code. When the data isn’t cached, even binary search can leak some information, via the number of distinct cache lines that are accessed.
I also completely ignored the question of shared resources (memory channels, particularly) on multicore chips: what happens to throughput when multiple cores are executing that kind of search workload? I’ll probably leave that to someone else ;)