This post was written under the influence of coffee ice cream and espresso. It’s a magical drink ;)

I don’t really follow the compression scene, and only pay minimal attention to machine learning. Nevertheless, the “Compression is Learning” slogan feels more and more right to me. In this post, I’ll explore another relationship that I find surprising: one between compression and compilation.
Five years ago, I took Marc Feeley’s compiler class, and he let us choose our term project. I settled on generating traces from recursive algorithms (typical of cache-oblivious algorithms) and reordering them to get iterative code that was better suited to the first level of cache. I came up with a gnarly CL-accented research-quality prototype, but the result was surprisingly effective. Sadly, I never really managed to recover loops or function calls from the fully inlined trace, so even medium-size kernels would exhaust the instruction cache.
I believe I now see a practical and scalable solution, thanks to Artur Jez’s work on “A really simple approximation of smallest grammar.” His work might lead to a function-oriented analogue of trace compilation. Trace compilers are notoriously weak on recursion (recursive function calls don’t map well to loops), so it would be nifty to have an alternative that identifies functions rather than loops.
This makes me quip that “(Trace) Compilation is Compression.” We can see trace compilers as lazily unpacking traces from the source program, rewriting them a bit, and recompressing traces in an executable format. Admittedly, the analogy is a bit of a stretch for classical compilers: they are less aggressive in decompressing source code and directly translate from one compressed representation (a small source file may describe billions of execution paths) to another.
Anyway… this is extremely hypothetical and Jez’s work is fun independently of my weekend speculations.
How to fail with LZ77
Once we cast a program trace as a sequence of opcodes (perhaps without operands, to expose more redundancy), it’s obvious that reducing code size is “just” compression, and LZ-type algorithms quickly come to mind: they compress strings by referring to earlier substrings.
The heart of LZ77 is a loop that streams through the input sequence and finds the longest common subsequence earlier in the input. In practice, the search usually considers a fixed-size window; when I write LZ77 here, I instead refer to the theoretical approach with an unbounded search window. Repeated LCS searches on an unbounded window sounds slow, but, in sophisticated implementations, the bottleneck is sorting the input string to generate a suffix array.
I don’t feel like being sophisticated and will implement a quadratic-time LCS search.
1 2 3 4 5 6 7 8 9 10 11 12 | |
Some backreferences clearly look like function calls.
1 2 3 4 5 6 | |
It’s a bit surprising at first, but some also correspond to repeat loops.
1 2 3 | |
This last patch is strange because it’s self-referential. However, if
we decompress character by character, its meaning becomes obvious: we
replicate the substring in [0, 1] to generate exactly 5 characters.
This is basically a loop; we can handle partial copies with, e.g.,
rotation and entering the middle of the loop (like Duff’s device).
Lempel and Ziv’s result tells us that we can look for references greedily in an unbounded window and obtain asymptotically optimal (proportional to the string’s entropy) compression. Again, there are algorithms to do that in linear time – via radix sort – but I’ll just bruteforce my way in cubic time.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
Here’s the problem with converting an LZ77 factorisation into calls and loops: there is no guarantee that patches nest sanely.
1 2 3 | |
This factorisation encodes “ababac||bac” by repeating “ab” two and a half times, inserting “c||”, and then repeating “bac.” The issue is that we wish to convert “ababa” into a loop, but the last patch would then need to enter that loop in its last iteration. We could also have the opposite problem, with a patch that only covers a prefix of an earlier patch (a few iterations of a loop). The sketch below shows how we might even have to deal with both issues in the same factor.

Jez’s solution
Jez’s paper analyses a method to recover a CFL with a single member, the string we wish to compress. The CFL is described by a fully deterministic (it produces exactly one string) CFG in Chomsky normal form, i.e., a straight-line program.
This “really simple” approach takes a step back from LZ compression and instead starts with the easiest, greedy, way to generate a straight-line program from a string: just pair characters as you encounter them, left-to-right.
For example, on “abab,” this would pair “(ab)(ab)” and then “((ab)(ab)),” and generate the following grammar:
G -> XX
X -> ab
We got lucky: the repetition synced up with the greedy pairing. That’s not always the case; for example, “abcab” becomes “(ab)(ca)b” – which exposes no redundancy – rather than “(ab)c(ab).”
Jez addresses this issue by using LZ77 factorisation as an oracle to synchronise pairings.
First, we simplify the algorithm by assuming that there are no factors that begin exactly one character before their output. Such factors correspond to repetitions of that one character (e.g., “aaaa” = “a” x 4) and we can easily turn them into repetitions of a pair (e.g., “aa” x 2).
It’s then simply a matter of not pairing when it would prevent the next character from synchronising with its backreference. For example, in “abcab,” we’d skip pairing “ca” so that “ab” could pair like the first occurrence did. We also don’t force a pair when the backreference only includes the first letter, but not the second. Finally, we opportunistically match consecutive unpaired letters.
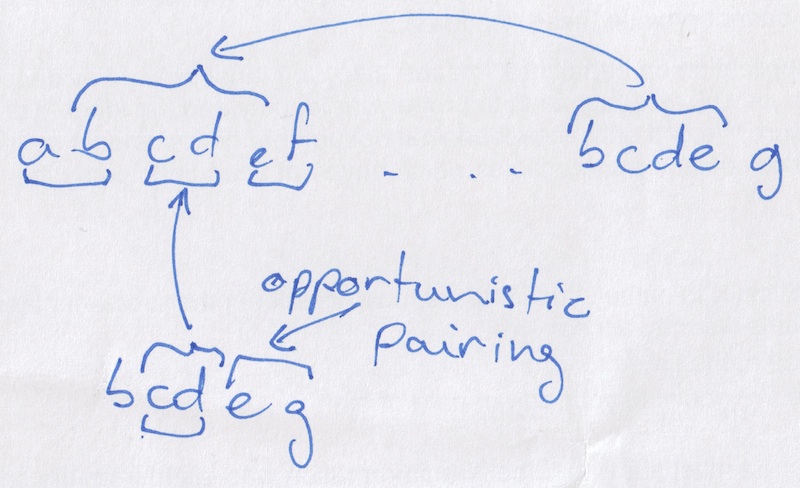
Each such pass creates a new, shorter, string of literals and production rules. We iteratively apply the guided pairing loop until we’re left with a single production rule.
That’s it. Jez’s paper is mostly concerned with showing that we only have to run LZ compression once and with proving suboptimality bounds. The key is that we can convert factors for the input into factors for the output, and that each pass shrinks the string by a multiplicative factor. I’ll simplify things further by recomputing a factorisation (in cubic time!) from scratch in each pass.
Now, the code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | |
My implementation is exceedingly naïve and runs in cubic time in the worst case. With a lot more work, the bottleneck (LZ77 factorisation) runs at the speed of sort… but constructing a suffix array would only get in the way of this post. Let’s just see what pairing the code generates.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
In short, “abcab” becomes “(ab)c(ab)”, “abababa” “(ab)(ab)(ab)a”, and “ababac||bac” “(ab)(ab)(ac)(||)b(ac)”.
Programs from pairs
So far, we’ve only made pairing decisions. The next step is to translate them into production rules (i.e., functions), and to merge equivalent rules to actually save space.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | |
On the examples above, we find:
1 2 3 4 5 6 7 8 9 10 11 | |
We only have to pair production rules further until the sequence consists of a single rule (or literal).
1 2 3 4 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
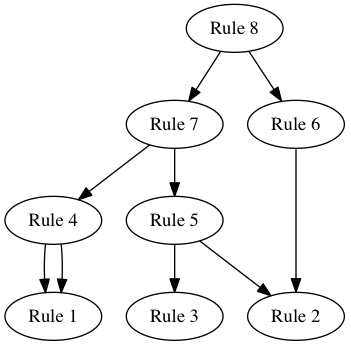
The “call graph” below shows there’s a lot of sharing for such a short string.
Enough with the strings
I started by writing about compiling program traces, but so far I’ve only been working with strings of characters. Let’s pretend the following PostScript file was written by someone who’s never heard of functions or loops.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Phew, programming is hard! That’s a lot of copy-paste to produce a simple pattern.
Let’s see what our (simplified) implementation of Jez’s algorithm can do.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
35 functions that each contain two literals or function calls. Not bad (: It’s an actual SMOP to convert this grammar into a PostScript program.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
This second PostScript program comprises 211 tokens, rather than the original’s 156, but 105 of those are “{ } def” noise to define functions. Arguably, the number of meaningful tokens was reduced from 156 to slightly more than 100. Crucially, the output remains the same.
Stack programs seem particularly well suited to this rewriting approach: explicit operands (e.g., registers) introduce trivial discrepancies. In a VM, I would consider “compressing” the opcode stream separately from the operands. Compiling only the former to native code would already reduce interpretative overhead, and extracting function calls from the instruction stream should avoid catastrophic size explosions.
There are several obvious deficiencies in the direct LZ77-guided
pairing. Just breaking Chomsky normalisation to inline single-use
function would already help. It might also make sense to special-case
repetitions as repeat n loops, instead of hiding that in
\(\log n\) levels of recursion. In a real program, it would also be
useful to inline the bottom-most rules so as not to drown in control
flow. The thing is, destroying structure in the name of performance
is well understood compiler tech; recovering it efficiently was the
hard part.